 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxGain: Regularisation of Neural Networks by Constraining Activation Magnitudes
Paper and Code
Jul 01, 2018
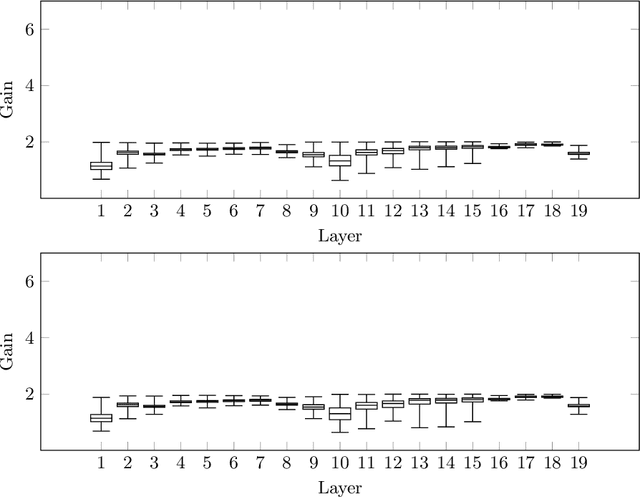

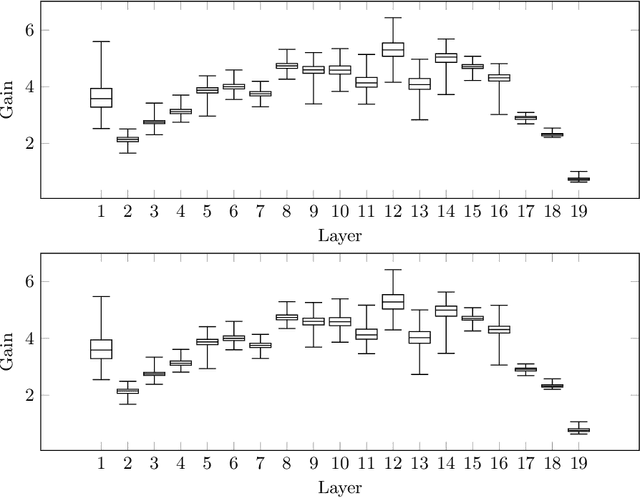
Effective regularisation of neural networks is essential to combat overfitting due to the large number of parameters involved. We present an empirical analogue to the Lipschitz constant of a feed-forward neural network, which we refer to as the maximum gain. We hypothesise that constraining the gain of a network will have a regularising effect, similar to how constraining the Lipschitz constant of a network has been shown to improve generalisation. A simple algorithm is provided that involves rescaling the weight matrix of each layer after each parameter update. We conduct a series of studies on common benchmark datasets, and also a novel dataset that we introduce to enable easier significance testing for experiments using convolutional networks. Performance on these datasets compares favourably with other common regularisation techniques.