 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularisation of Neural Networks by Enforcing Lipschitz Continuity
Sep 14, 2018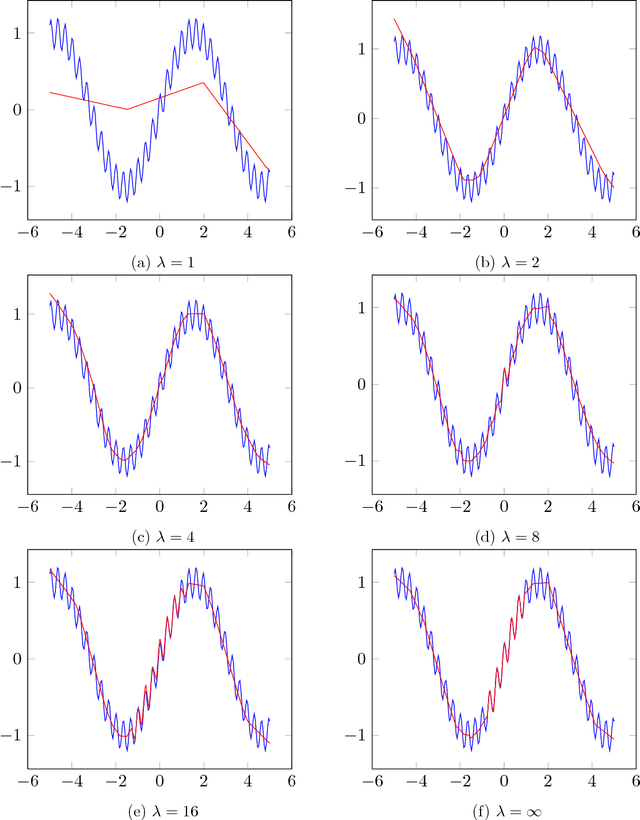
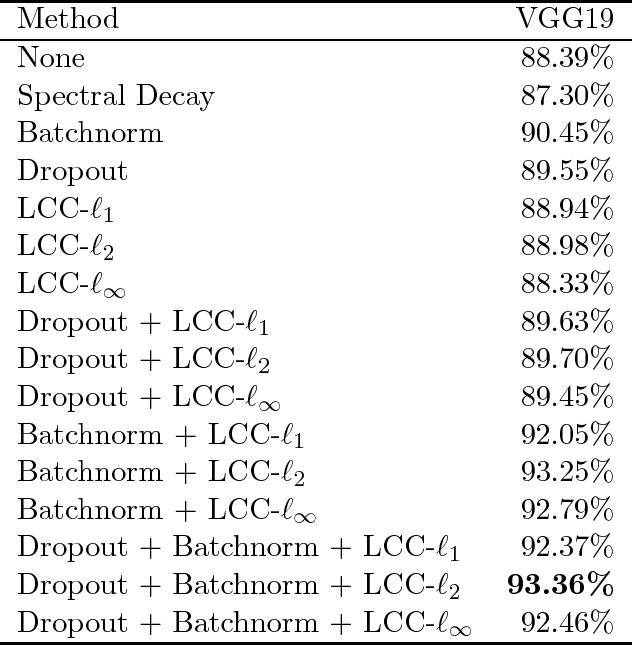
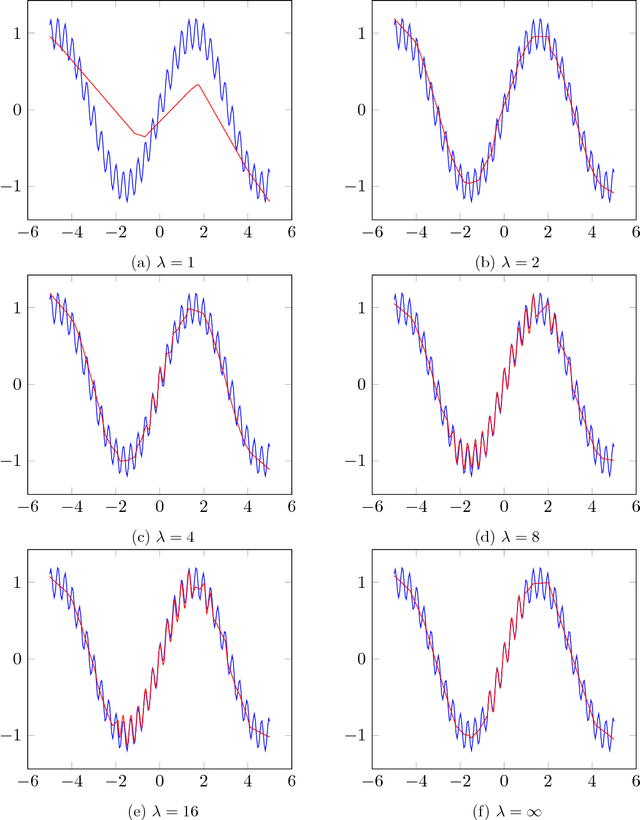
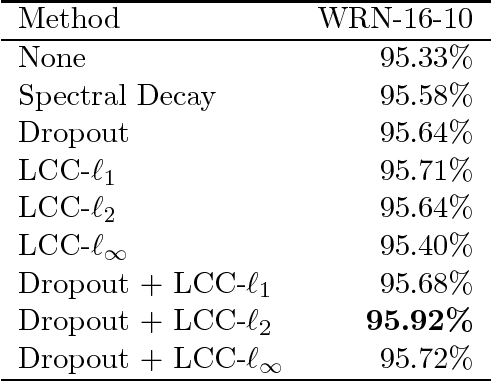
We investigate the effect of explicitly enforcing the Lipschitz continuity of neural networks with respect to their inputs. To this end, we provide a simple technique for computing an upper bound to the Lipschitz constant of a feed forward neural network composed of commonly used layer types and demonstrate inaccuracies in previous work on this topic. Our technique is then used to formulate training a neural network with a bounded Lipschitz constant as a constrained optimisation problem that can be solved using projected stochastic gradient methods. Our evaluation study shows that, in isolation, our method performs comparatively to state-of-the-art regularisation techniques. Moreover, when combined with existing approaches to regularising neural networks the performance gains are cumulative. We also provide evidence that the hyperparameters are intuitive to tune and demonstrate how the choice of norm for computing the Lipschitz constant impacts the resulting model.
MaxGain: Regularisation of Neural Networks by Constraining Activation Magnitudes
Jul 01, 2018
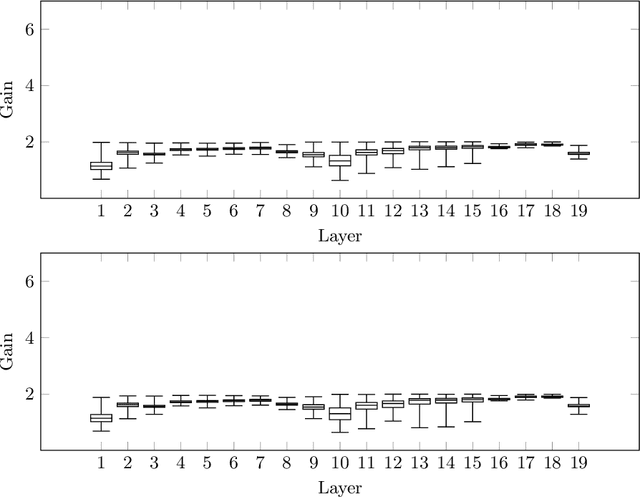

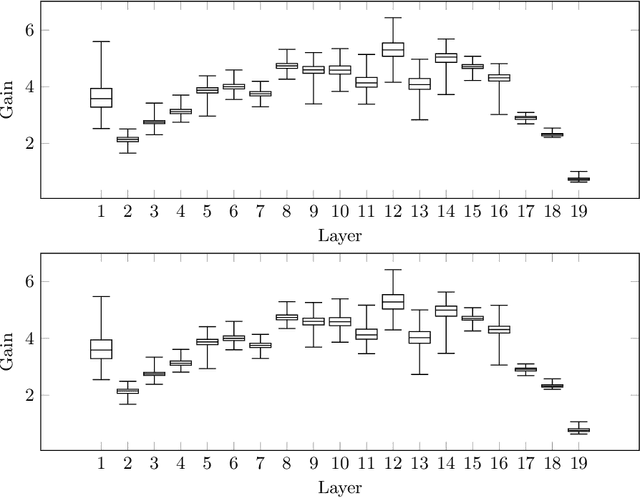
Effective regularisation of neural networks is essential to combat overfitting due to the large number of parameters involved. We present an empirical analogue to the Lipschitz constant of a feed-forward neural network, which we refer to as the maximum gain. We hypothesise that constraining the gain of a network will have a regularising effect, similar to how constraining the Lipschitz constant of a network has been shown to improve generalisation. A simple algorithm is provided that involves rescaling the weight matrix of each layer after each parameter update. We conduct a series of studies on common benchmark datasets, and also a novel dataset that we introduce to enable easier significance testing for experiments using convolutional networks. Performance on these datasets compares favourably with other common regularisation techniques.
Fast Metric Learning For Deep Neural Networks
Apr 05, 2016
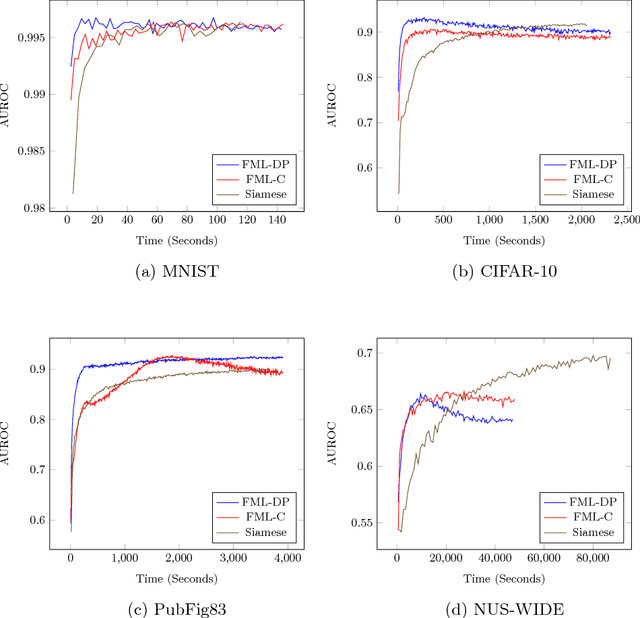

Similarity metrics are a core component of many information retrieval and machine learning systems. In this work we propose a method capable of learning a similarity metric from data equipped with a binary relation. By considering only the similarity constraints, and initially ignoring the features, we are able to learn target vectors for each instance using one of several appropriately designed loss functions. A regression model can then be constructed that maps novel feature vectors to the same target vector space, resulting in a feature extractor that computes vectors for which a predefined metric is a meaningful measure of similarity. We present results on both multiclass and multi-label classification datasets that demonstrate considerably faster convergence, as well as higher accuracy on the majority of the intrinsic evaluation tasks and all extrinsic evaluation tasks.