 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Gradient-Based Learning in Continuous Games
Paper and Code
Sep 27, 2018
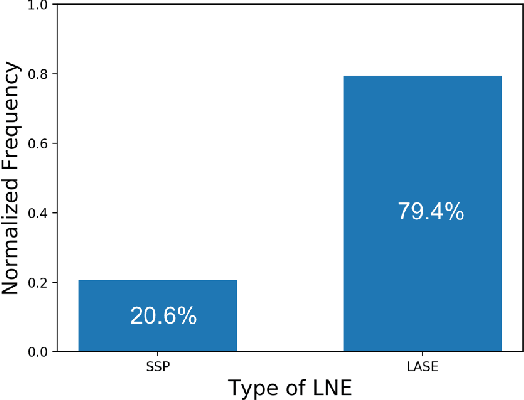
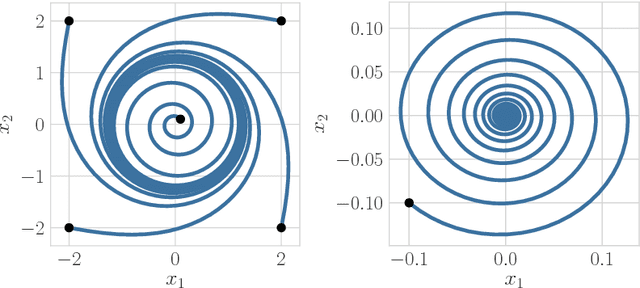
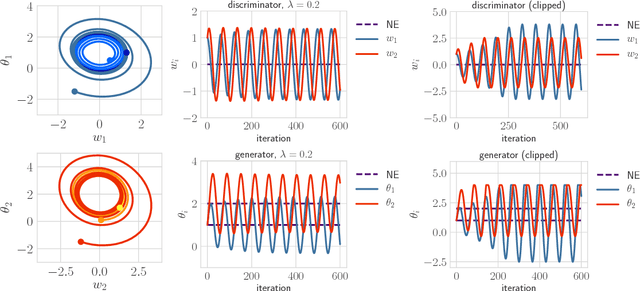
We study the limiting behavior of competitive agents employing gradient-based learning algorithms through the lens of dynamical systems theory. Specifically, we introduce a general framework for competitive gradient-based learning that allows us to analyze a wide breadth of learning algorithms including policy gradient reinforcement learning, gradient based bandits, and certain online convex optimization algorithms. We show that for both potential games and general-sum games, when agents employ gradient-based learning algorithms, they will avoid a non-negligible subset of the local Nash equilibria. This is a strongly negative result for gradient-based learning in games. Our framework also sheds light on the issue of convergence to non-Nash strategies in general-sum and zero-sum games which have no relevance to the underlying game, and arise solely due to the choice of algorithm. The existence and frequency of strategies may explain some of the difficulties encountered when using gradient descent in zero-sum games (e.g. to train generative adversarial networks). Finally, we introduce a new class of games, Morse-Smale games, for which the gradient dynamics correspond to gradient-like flows. This class encompasses a large set of commonly encountered games. For Morse-Smale games, we show that competitive gradient-based learning converges to either limit cycles, Nash equilibria, or non-Nash fixed points almost surely. To reinforce our theoretical contributions, we provide empirical results that highlight the frequency of Nash equilibria that are almost surely avoided by policy gradient in linear quadratic games. Indeed, we present empirical results that show that policy gradient almost surely avoids the unique global Nash equilibrium in one out of five randomly sampled linear quadratic games.