 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of methods for model selection when estimating individual treatment effects
Paper and Code
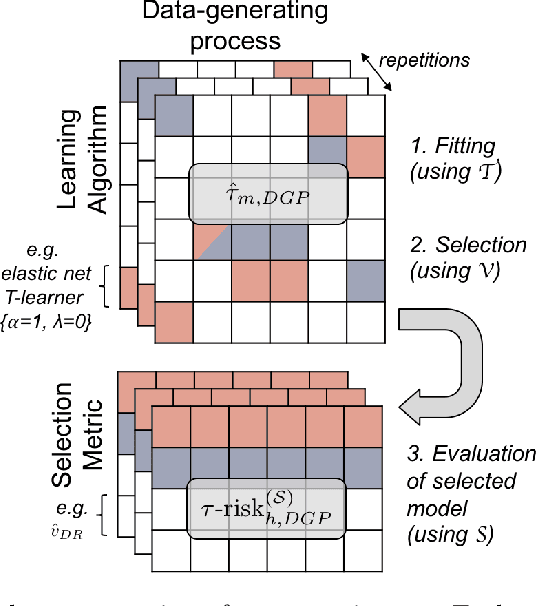
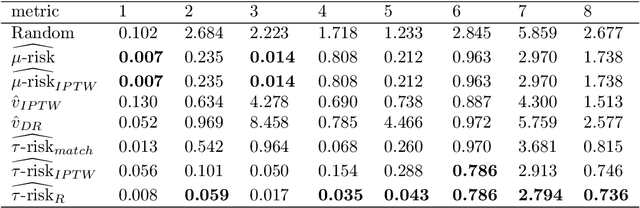
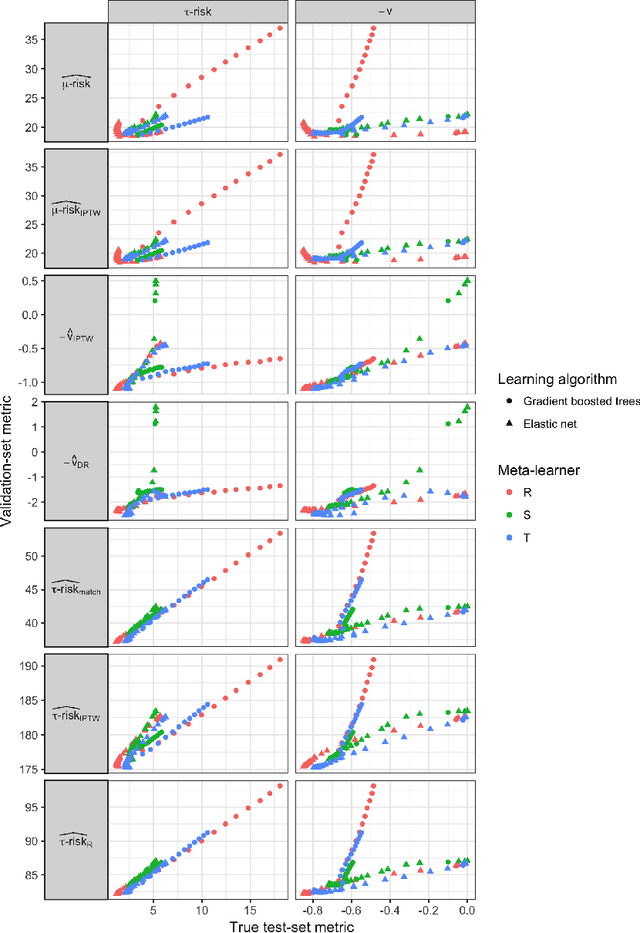
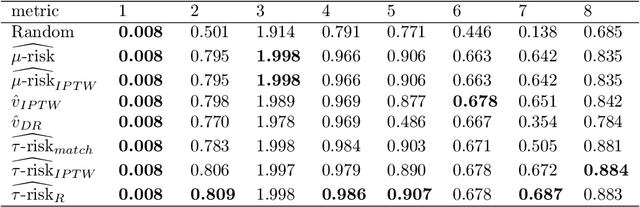
Practitioners in medicine, business, political science, and other fields are increasingly aware that decisions should be personalized to each patient, customer, or voter. A given treatment (e.g. a drug or advertisement) should be administered only to those who will respond most positively, and certainly not to those who will be harmed by it. Individual-level treatment effects can be estimated with tools adapted from machine learning, but different models can yield contradictory estimates. Unlike risk prediction models, however, treatment effect models cannot be easily evaluated against each other using a held-out test set because the true treatment effect itself is never directly observed. Besides outcome prediction accuracy, several metrics that can leverage held-out data to evaluate treatment effects models have been proposed, but they are not widely used. We provide a didactic framework that elucidates the relationships between the different approaches and compare them all using a variety of simulations of both randomized and observational data. Our results show that researchers estimating heterogenous treatment effects need not limit themselves to a single model-fitting algorithm. Instead of relying on a single method, multiple models fit by a diverse set of algorithms should be evaluated against each other using an objective function learned from the validation set. The model minimizing that objective should be used for estimating the individual treatment effect for future individuals.