 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularisation of Neural Networks by Enforcing Lipschitz Continuity
Paper and Code
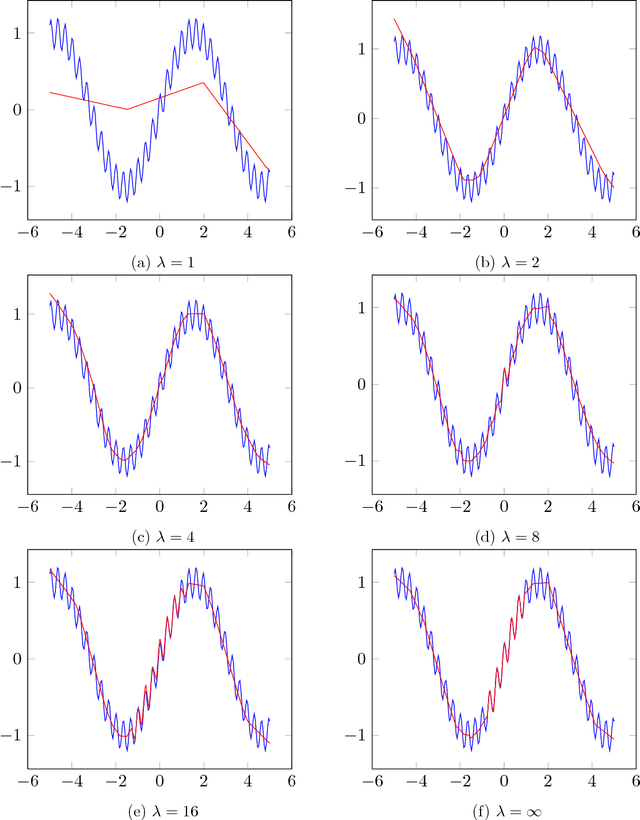
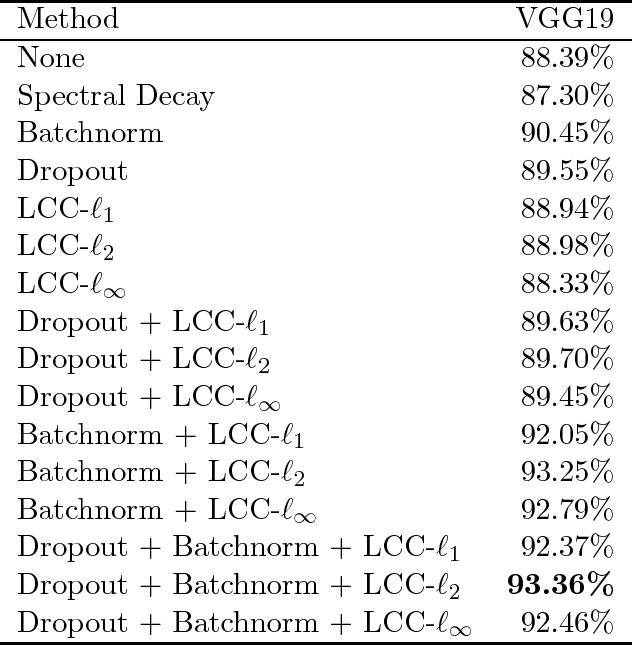
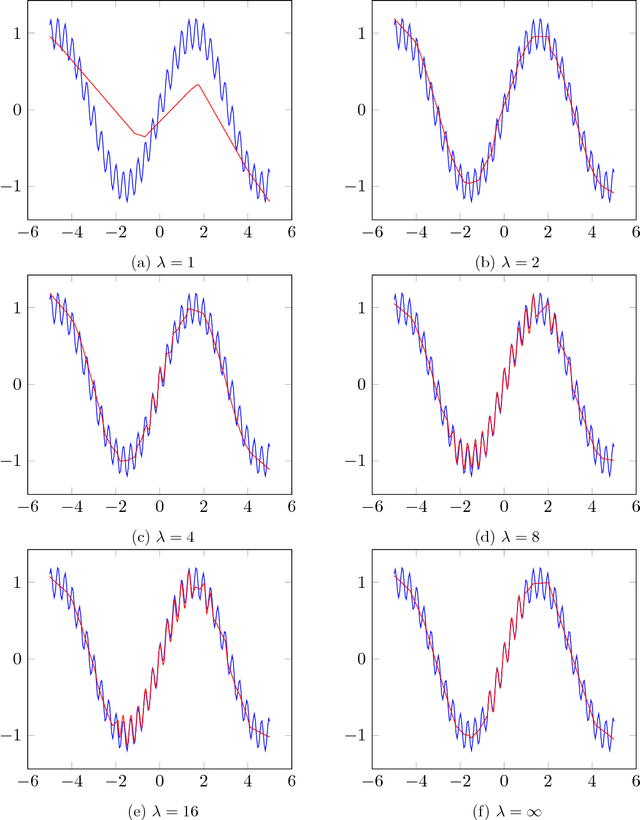
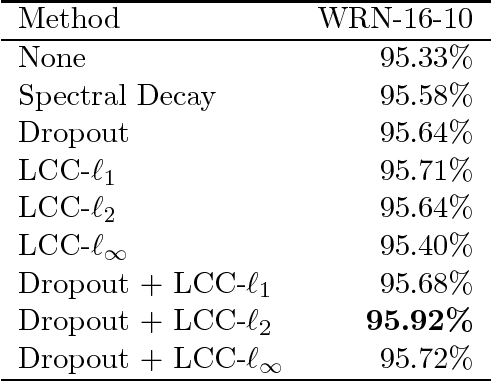
We investigate the effect of explicitly enforcing the Lipschitz continuity of neural networks with respect to their inputs. To this end, we provide a simple technique for computing an upper bound to the Lipschitz constant of a feed forward neural network composed of commonly used layer types and demonstrate inaccuracies in previous work on this topic. Our technique is then used to formulate training a neural network with a bounded Lipschitz constant as a constrained optimisation problem that can be solved using projected stochastic gradient methods. Our evaluation study shows that, in isolation, our method performs comparatively to state-of-the-art regularisation techniques. Moreover, when combined with existing approaches to regularising neural networks the performance gains are cumulative. We also provide evidence that the hyperparameters are intuitive to tune and demonstrate how the choice of norm for computing the Lipschitz constant impacts the resulting model.