 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Twitter User Socioeconomic Attributes with Network and Language Information
Paper and Code
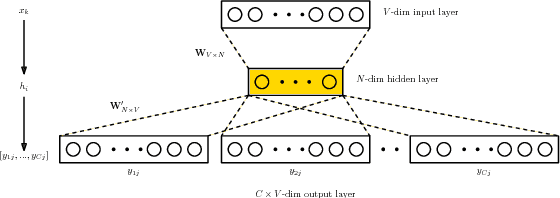
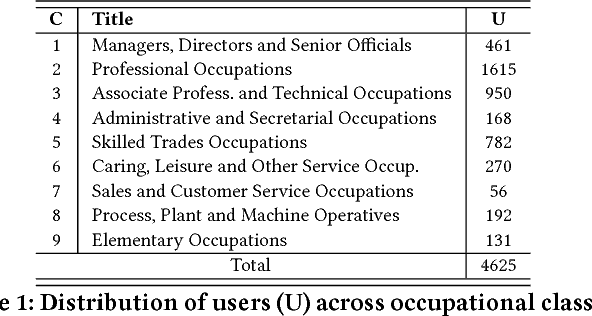
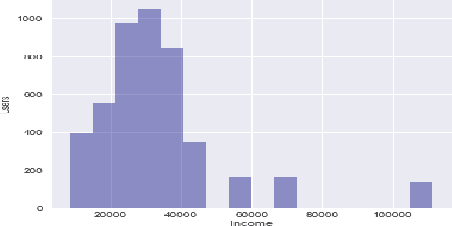
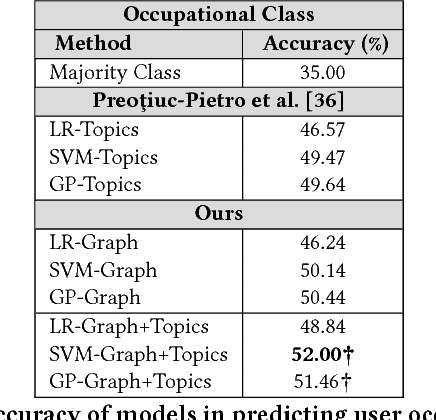
Inferring socioeconomic attributes of social media users such as occupation and income is an important problem in computational social science. Automated inference of such characteristics has applications in personalised recommender systems, targeted computational advertising and online political campaigning. While previous work has shown that language features can reliably predict socioeconomic attributes on Twitter, employing information coming from users' social networks has not yet been explored for such complex user characteristics. In this paper, we describe a method for predicting the occupational class and the income of Twitter users given information extracted from their extended networks by learning a low-dimensional vector representation of users, i.e. graph embeddings. We use this representation to train predictive models for occupational class and income. Results on two publicly available datasets show that our method consistently outperforms the state-of-the-art methods in both tasks. We also obtain further significant improvements when we combine graph embeddings with textual features, demonstrating that social network and language information are complementary.