 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Modeling with Generative Adversarial Networks
Paper and Code
Apr 08, 2018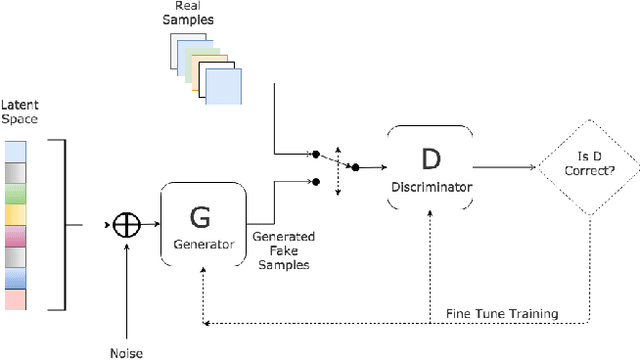



Generative Adversarial Networks (GANs) have been promising in the field of image generation, however, they have been hard to train for language generation. GANs were originally designed to output differentiable values, so discrete language generation is challenging for them which causes high levels of instability in training GANs. Consequently, past work has resorted to pre-training with maximum-likelihood or training GANs without pre-training with a WGAN objective with a gradient penalty. In this study, we present a comparison of those approaches. Furthermore, we present the results of some experiments that indicate better training and convergence of Wasserstein GANs (WGANs) when a weaker regularization term is enforcing the Lipschitz constraint.