 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability and Convergence Trade-off of Iterative Optimization Algorithms
Paper and Code

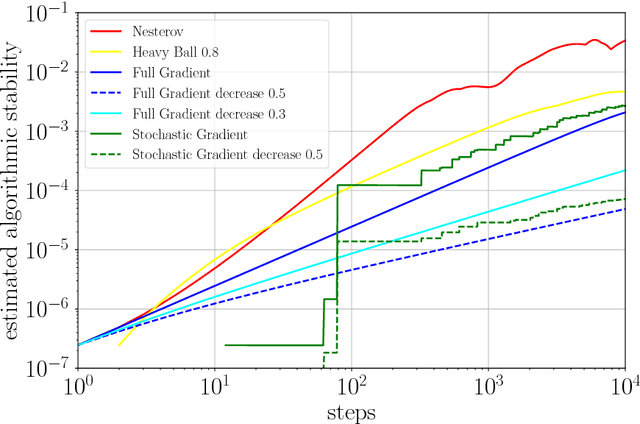
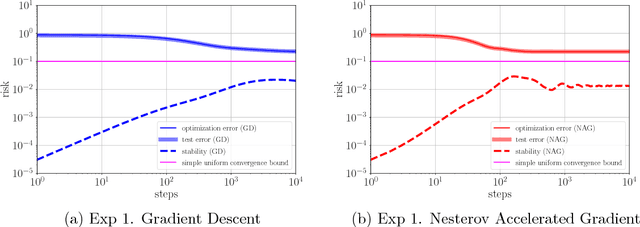
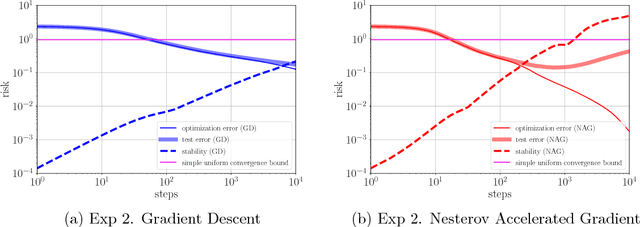
The overall performance or expected excess risk of an iterative machine learning algorithm can be decomposed into training error and generalization error. While the former is controlled by its convergence analysis, the latter can be tightly handled by algorithmic stability. The machine learning community has a rich history investigating convergence and stability separately. However, the question about the trade-off between these two quantities remains open. In this paper, we show that for any iterative algorithm at any iteration, the overall performance is lower bounded by the minimax statistical error over an appropriately chosen loss function class. This implies an important trade-off between convergence and stability of the algorithm -- a faster converging algorithm has to be less stable, and vice versa. As a direct consequence of this fundamental tradeoff, new convergence lower bounds can be derived for classes of algorithms constrained with different stability bounds. In particular, when the loss function is convex (or strongly convex) and smooth, we discuss the stability upper bounds of gradient descent (GD) and stochastic gradient descent and their variants with decreasing step sizes. For Nesterov's accelerated gradient descent (NAG) and heavy ball method (HB), we provide stability upper bounds for the quadratic loss function. Applying existing stability upper bounds for the gradient methods in our trade-off framework, we obtain lower bounds matching the well-established convergence upper bounds up to constants for these algorithms and conjecture similar lower bounds for NAG and HB. Finally, we numerically demonstrate the tightness of our stability bounds in terms of exponents in the rate and also illustrate via a simulated logistic regression problem that our stability bounds reflect the generalization errors better than the simple uniform convergence bounds for GD and NAG.