 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Talking Face Landmarks from Speech
Paper and Code
Apr 23, 2018
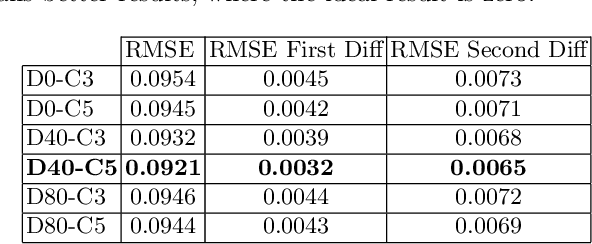
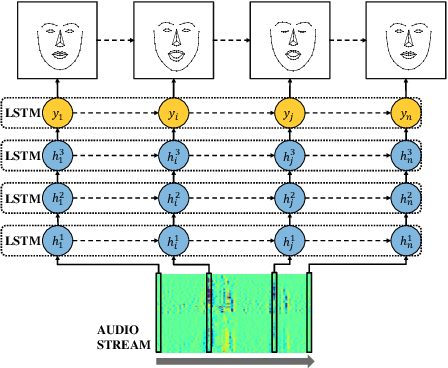

The presence of a corresponding talking face has been shown to significantly improve speech intelligibility in noisy conditions and for hearing impaired population. In this paper, we present a system that can generate landmark points of a talking face from an acoustic speech in real time. The system uses a long short-term memory (LSTM) network and is trained on frontal videos of 27 different speakers with automatically extracted face landmarks. After training, it can produce talking face landmarks from the acoustic speech of unseen speakers and utterances. The training phase contains three key steps. We first transform landmarks of the first video frame to pin the two eye points into two predefined locations and apply the same transformation on all of the following video frames. We then remove the identity information by transforming the landmarks into a mean face shape across the entire training dataset. Finally, we train an LSTM network that takes the first- and second-order temporal differences of the log-mel spectrogram as input to predict face landmarks in each frame. We evaluate our system using the mean-squared error (MSE) loss of landmarks of lips between predicted and ground-truth landmarks as well as their first- and second-order temporal differences. We further evaluate our system by conducting subjective tests, where the subjects try to distinguish the real and fake videos of talking face landmarks. Both tests show promising results.