 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDNet: Prior-model Guided Depth-enhanced Network for Salient Object Detection
Paper and Code
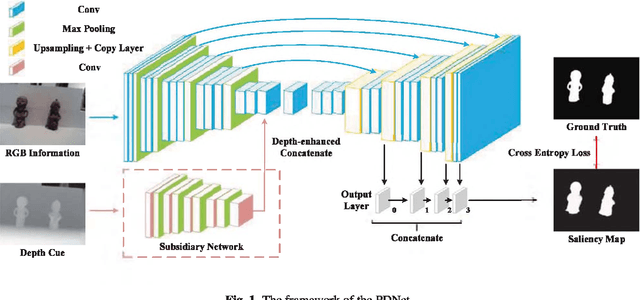
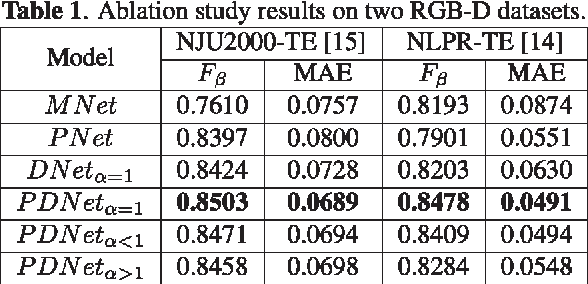

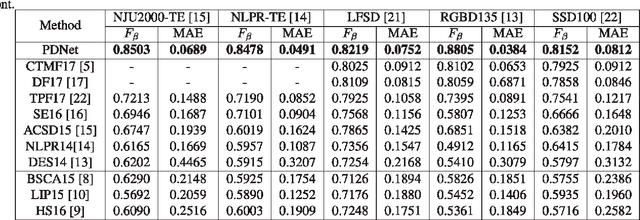
Fully convolutional neural networks (FCNs) have shown outstanding performance in many computer vision tasks including salient object detection. However, there still remains two issues needed to be addressed in deep learning based saliency detection. One is the lack of tremendous amount of annotated data to train a network. The other is the lack of robustness for extracting salient objects in images containing complex scenes. In this paper, we present a new architecture$ - $PDNet, a robust prior-model guided depth-enhanced network for RGB-D salient object detection. In contrast to existing works, in which RGB-D values of image pixels are fed directly to a network, the proposed architecture is composed of a master network for processing RGB values, and a sub-network making full use of depth cues and incorporate depth-based features into the master network. To overcome the limited size of the labeled RGB-D dataset for training, we employ a large conventional RGB dataset to pre-train the master network, which proves to contribute largely to the final accuracy. Extensive evaluations over five benchmark datasets demonstrate that our proposed method performs favorably against the state-of-the-art approaches.