 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Object Segmentation with Joint Re-identification and Attention-Aware Mask Propagation
Paper and Code

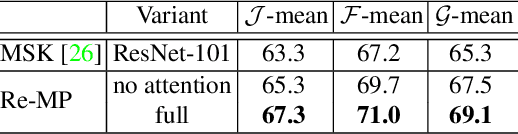
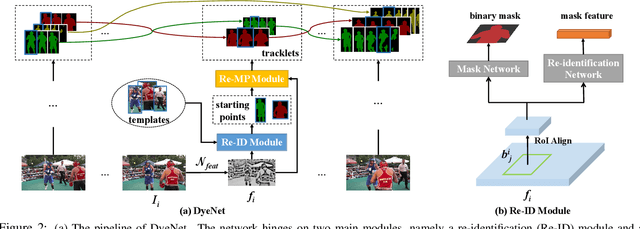

The problem of video object segmentation can become extremely challenging when multiple instances co-exist. While each instance may exhibit large scale and pose variations, the problem is compounded when instances occlude each other causing failures in tracking. In this study, we formulate a deep recurrent network that is capable of segmenting and tracking objects in video simultaneously by their temporal continuity, yet able to re-identify them when they re-appear after a prolonged occlusion. We combine both temporal propagation and re-identification functionalities into a single framework that can be trained end-to-end. In particular, we present a re-identification module with template expansion to retrieve missing objects despite their large appearance changes. In addition, we contribute a new attention-based recurrent mask propagation approach that is robust to distractors not belonging to the target segment. Our approach achieves a new state-of-the-art global mean (Region Jaccard and Boundary F measure) of 68.2 on the challenging DAVIS 2017 benchmark (test-dev set), outperforming the winning solution which achieves a global mean of 66.1 on the same partition.