 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Start Training: The Effect of Initialization and Architecture
Paper and Code
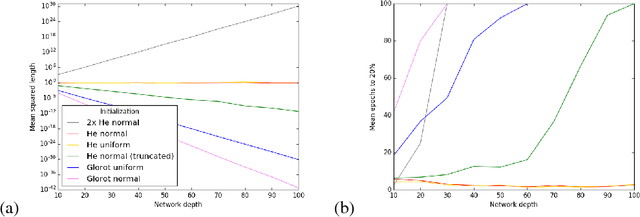
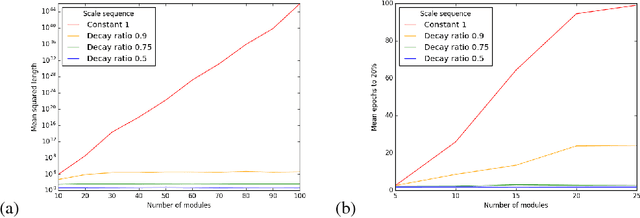
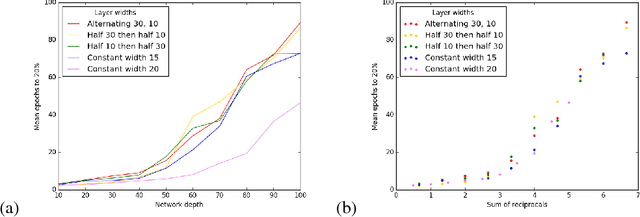
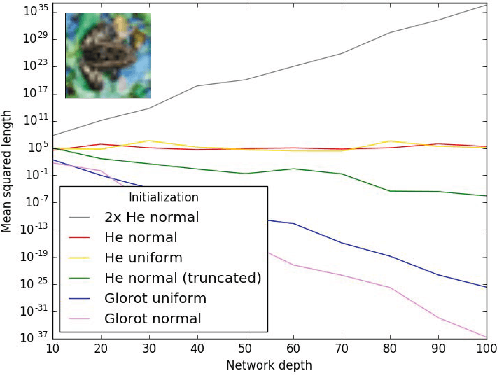
We identify and study two common failure modes for early training in deep ReLU nets. For each we give a rigorous proof of when it occurs and how to avoid it, for fully connected and residual architectures. The first failure mode, exploding/vanishing mean activation length, can be avoided by initializing weights from a symmetric distribution with variance 2/fan-in and, for ResNets, by correctly weighting the residual modules. We prove that the second failure mode, exponentially large variance of activation length, never occurs in residual nets once the first failure mode is avoided. In contrast, for fully connected nets, we prove that this failure mode can happen and is avoided by keeping constant the sum of the reciprocals of layer widths. We demonstrate empirically the effectiveness of our theoretical results in predicting when networks are able to start training. In particular, we note that many popular initializations fail our criteria, whereas correct initialization and architecture allows much deeper networks to be trained.