 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Explainability of Capsule Networks: Relevance Path by Agreement
Paper and Code
Feb 27, 2018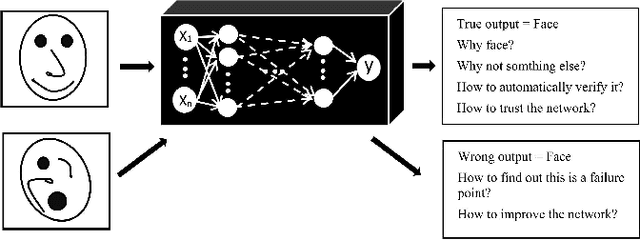
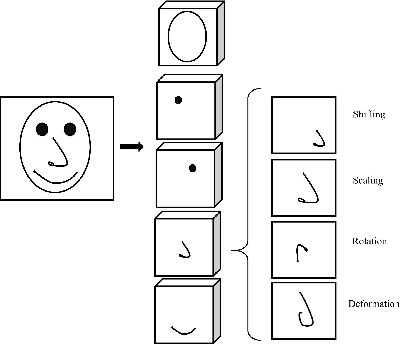
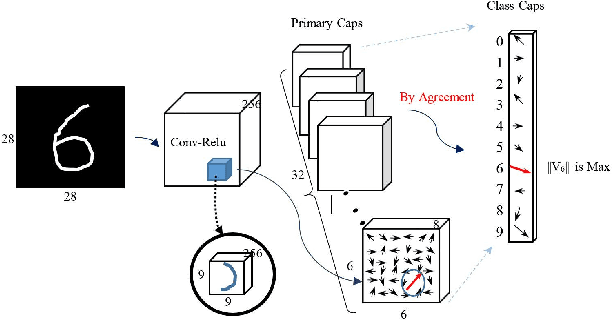
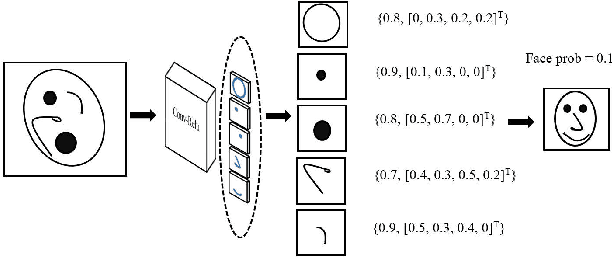
Recent advancements in signal processing and machine learning domains have resulted in an extensive surge of interest in deep learning models due to their unprecedented performance and high accuracy for different and challenging problems of significant engineering importance. However, when such deep learning architectures are utilized for making critical decisions such as the ones that involve human lives (e.g., in medical applications), it is of paramount importance to understand, trust, and in one word "explain" the rational behind deep models' decisions. Currently, deep learning models are typically considered as black-box systems, which do not provide any clue on their internal processing actions. Although some recent efforts have been initiated to explain behavior and decisions of deep networks, explainable artificial intelligence (XAI) domain is still in its infancy. In this regard, we consider capsule networks (referred to as CapsNets), which are novel deep structures; recently proposed as an alternative counterpart to convolutional neural networks (CNNs), and posed to change the future of machine intelligence. In this paper, we investigate and analyze structures and behaviors of the CapsNets and illustrate potential explainability properties of such networks. Furthermore, we show possibility of transforming deep learning architectures in to transparent networks via incorporation of capsules in different layers instead of convolution layers of the CNNs.