 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Feed-forward Sequential Memory Networks for Speech Synthesis
Paper and Code
Feb 26, 2018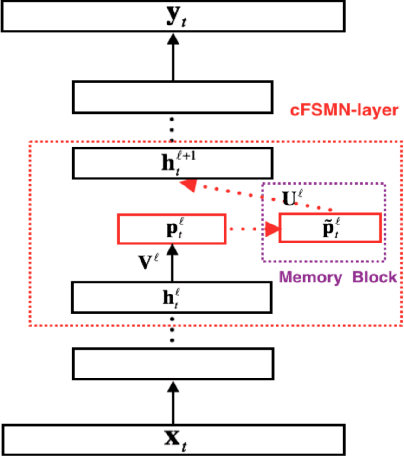
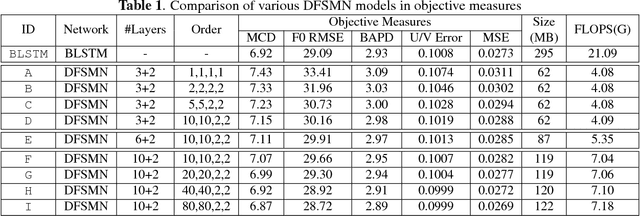
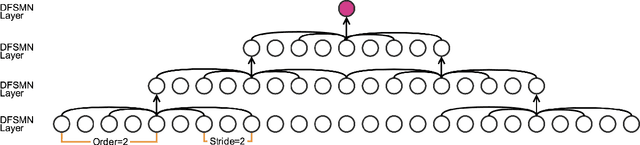
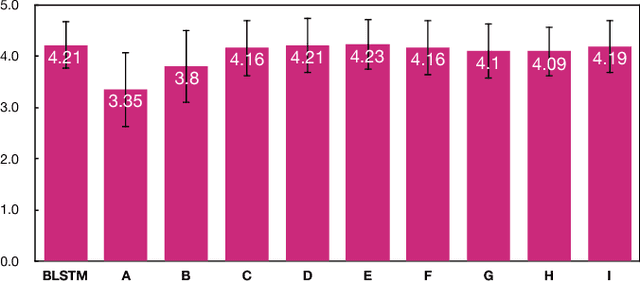
The Bidirectional LSTM (BLSTM) RNN based speech synthesis system is among the best parametric Text-to-Speech (TTS) systems in terms of the naturalness of generated speech, especially the naturalness in prosody. However, the model complexity and inference cost of BLSTM prevents its usage in many runtime applications. Meanwhile, Deep Feed-forward Sequential Memory Networks (DFSMN) has shown its consistent out-performance over BLSTM in both word error rate (WER) and the runtime computation cost in speech recognition tasks. Since speech synthesis also requires to model long-term dependencies compared to speech recognition, in this paper, we investigate the Deep-FSMN (DFSMN) in speech synthesis. Both objective and subjective experiments show that, compared with BLSTM TTS method, the DFSMN system can generate synthesized speech with comparable speech quality while drastically reduce model complexity and speech generation time.