 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Evaluation and Optimization with Continuous Treatments
Paper and Code
Feb 16, 2018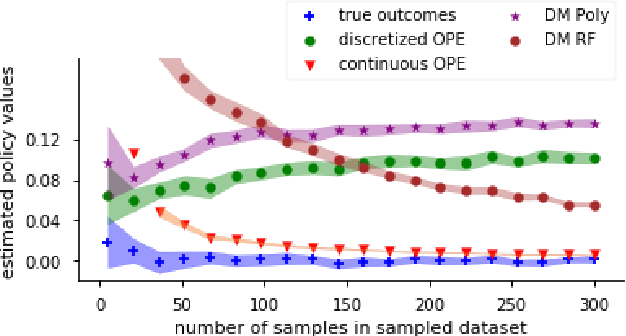
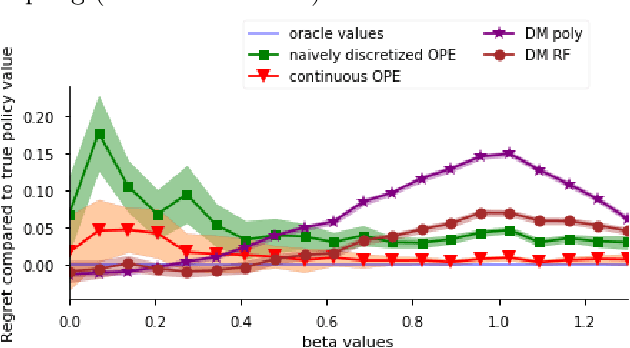
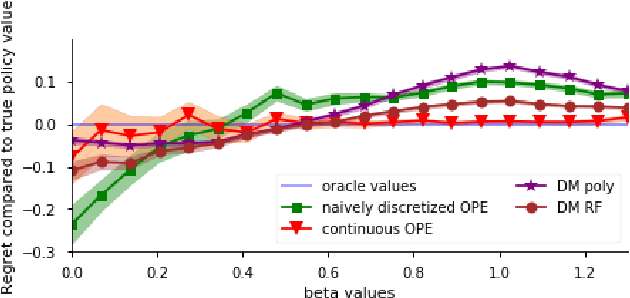
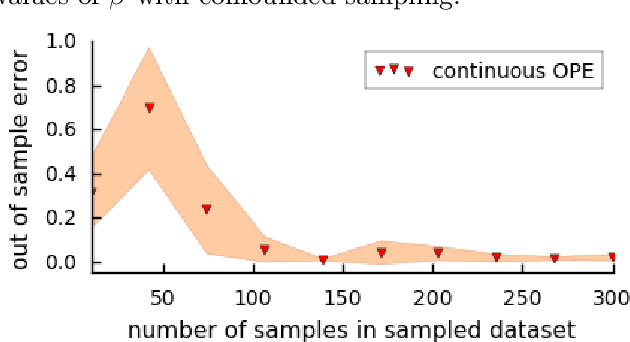
We study the problem of policy evaluation and learning from batched contextual bandit data when treatments are continuous, going beyond previous work on discrete treatments. Previous work for discrete treatment/action spaces focuses on inverse probability weighting (IPW) and doubly robust (DR) methods that use a rejection sampling approach for evaluation and the equivalent weighted classification problem for learning. In the continuous setting, this reduction fails as we would almost surely reject all observations. To tackle the case of continuous treatments, we extend the IPW and DR approaches to the continuous setting using a kernel function that leverages treatment proximity to attenuate discrete rejection. Our policy estimator is consistent and we characterize the optimal bandwidth. The resulting continuous policy optimizer (CPO) approach using our estimator achieves convergent regret and approaches the best-in-class policy for learnable policy classes. We demonstrate that the estimator performs well and, in particular, outperforms a discretization-based benchmark. We further study the performance of our policy optimizer in a case study on personalized dosing based on a dataset of Warfarin patients, their covariates, and final therapeutic doses. Our learned policy outperforms benchmarks and nears the oracle-best linear policy.