 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Disentangled Embeddings with the F-Statistic Loss
Paper and Code
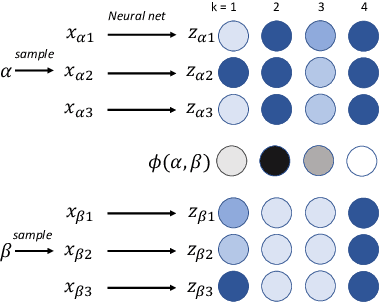
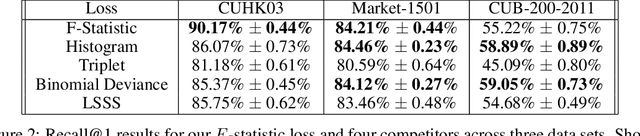
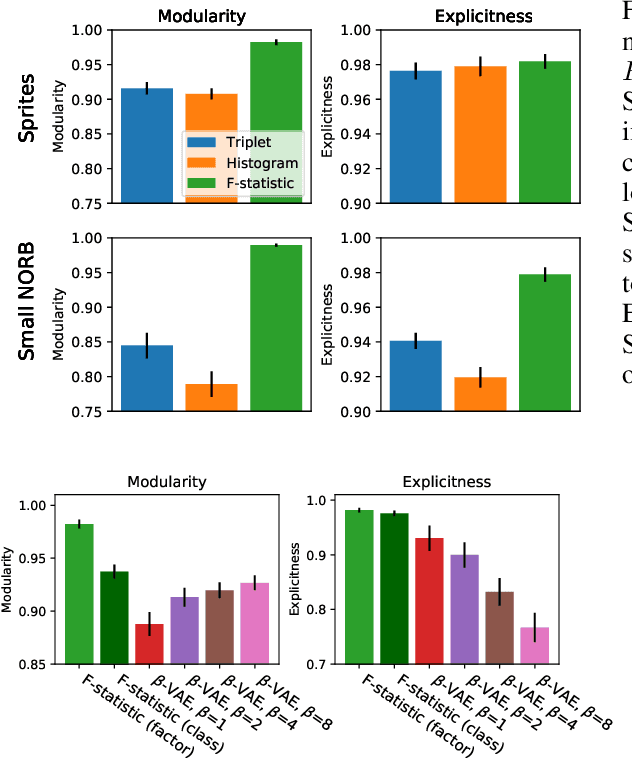
Deep-embedding methods aim to discover representations of a domain that make explicit the domain's class structure and thereby support few-shot learning. Disentangling methods aim to make explicit compositional or factorial structure. We combine these two active but independent lines of research and propose a new paradigm suitable for both goals. We propose and evaluate a novel loss function based on the $F$ statistic, which describes the separation of two or more distributions. By ensuring that distinct classes are well separated on a subset of embedding dimensions, we obtain embeddings that are useful for few-shot learning. By not requiring separation on all dimensions, we encourage the discovery of disentangled representations. Our embedding method matches or beats state-of-the-art, as evaluated by performance on recall@$k$ and few-shot learning tasks. Our method also obtains performance superior to a variety of alternatives on disentangling, as evaluated by two key properties of a disentangled representation: modularity and explicitness. The goal of our work is to obtain more interpretable, manipulable, and generalizable deep representations of concepts and categories.