Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextZoo, a New Benchmark for Reconsidering Text Classification
Paper and Code
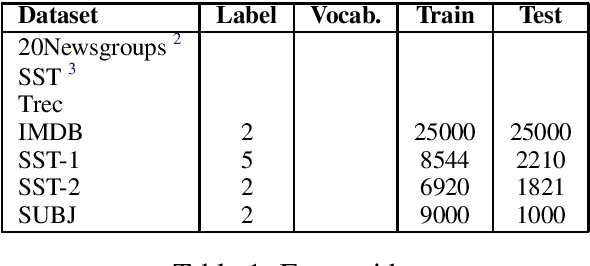
Text representation is a fundamental concern in Natural Language Processing, especially in text classification. Recently, many neural network approaches with delicate representation model (e.g. FASTTEXT, CNN, RNN and many hybrid models with attention mechanisms) claimed that they achieved state-of-art in specific text classification datasets. However, it lacks an unified benchmark to compare these models and reveals the advantage of each sub-components for various settings. We re-implement more than 20 popular text representation models for classification in more than 10 datasets. In this paper, we reconsider the text classification task in the perspective of neural network and get serval effects with analysis of the above results.
* a benchmark need to be completed
View paper on