 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Non-decomposable Measures with Deep Networks
Paper and Code
Jan 31, 2018
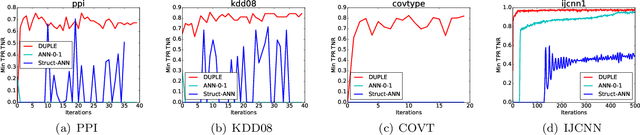
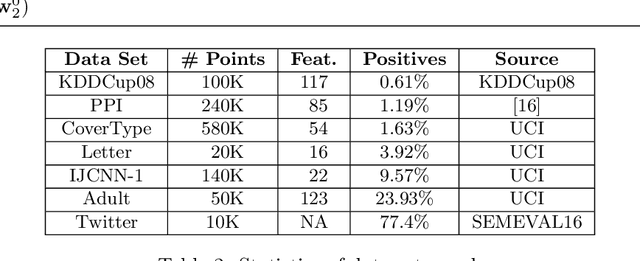
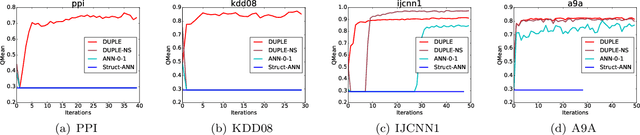
We present a class of algorithms capable of directly training deep neural networks with respect to large families of task-specific performance measures such as the F-measure and the Kullback-Leibler divergence that are structured and non-decomposable. This presents a departure from standard deep learning techniques that typically use squared or cross-entropy loss functions (that are decomposable) to train neural networks. We demonstrate that directly training with task-specific loss functions yields much faster and more stable convergence across problems and datasets. Our proposed algorithms and implementations have several novel features including (i) convergence to first order stationary points despite optimizing complex objective functions; (ii) use of fewer training samples to achieve a desired level of convergence, (iii) a substantial reduction in training time, and (iv) a seamless integration of our implementation into existing symbolic gradient frameworks. We implement our techniques on a variety of deep architectures including multi-layer perceptrons and recurrent neural networks and show that on a variety of benchmark and real data sets, our algorithms outperform traditional approaches to training deep networks, as well as some recent approaches to task-specific training of neural networks.