Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Multitasking: Analyzing and Improving Syntactic Saliency of Hidden Representations
Paper and Code
Jan 18, 2018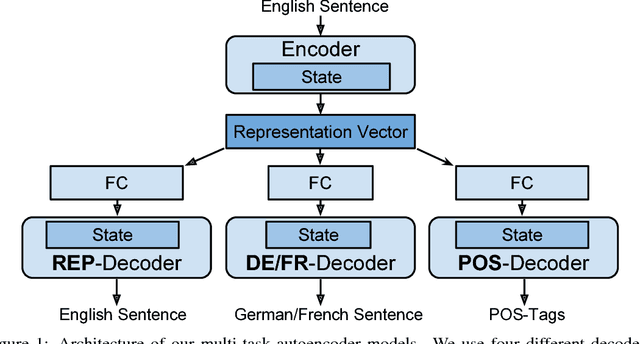
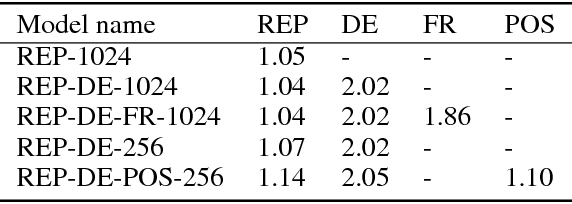


We train multi-task autoencoders on linguistic tasks and analyze the learned hidden sentence representations. The representations change significantly when translation and part-of-speech decoders are added. The more decoders a model employs, the better it clusters sentences according to their syntactic similarity, as the representation space becomes less entangled. We explore the structure of the representation space by interpolating between sentences, which yields interesting pseudo-English sentences, many of which have recognizable syntactic structure. Lastly, we point out an interesting property of our models: The difference-vector between two sentences can be added to change a third sentence with similar features in a meaningful way.
* The 31st Annual Conference on Neural Information Processing (NIPS) -
Workshop on Learning Disentangled Features: from Perception to Control, Long
Beach, CA, December 2017
View paper on