 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Propensity Score Computation Method based on Machine Learning with Label-corrupted Data
Paper and Code
Jan 09, 2018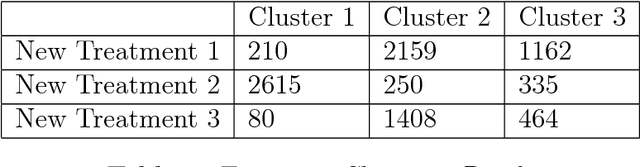
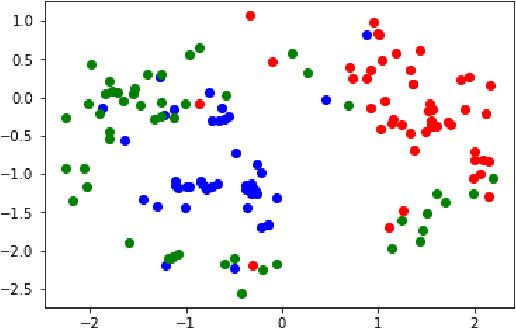
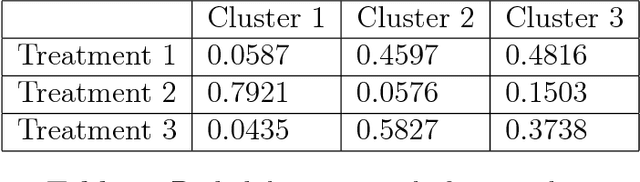
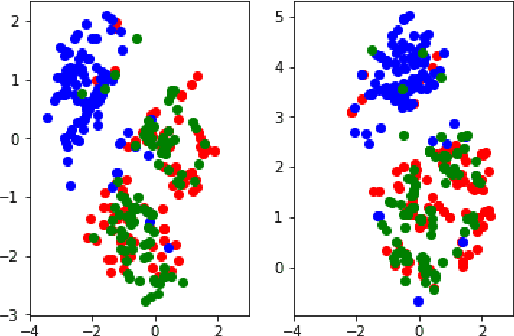
In biostatistics, propensity score is a common approach to analyze the imbalance of covariate and process confounding covariates to eliminate differences between groups. While there are an abundant amount of methods to compute propensity score, a common issue of them is the corrupted labels in the dataset. For example, the data collected from the patients could contain samples that are treated mistakenly, and the computing methods could incorporate them as a misleading information. In this paper, we propose a Machine Learning-based method to handle the problem. Specifically, we utilize the fact that the majority of sample should be labeled with the correct instance and design an approach to first cluster the data with spectral clustering and then sample a new dataset with a distribution processed from the clustering results. The propensity score is computed by Xgboost, and a mathematical justification of our method is provided in this paper. The experimental results illustrate that xgboost propensity scores computing with the data processed by our method could outperform the same method with original data, and the advantages of our method increases as we add some artificial corruptions to the dataset. Meanwhile, the implementation of xgboost to compute propensity score for multiple treatments is also a pioneering work in the area.