Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvexification of Neural Graph
Paper and Code
Jan 13, 2018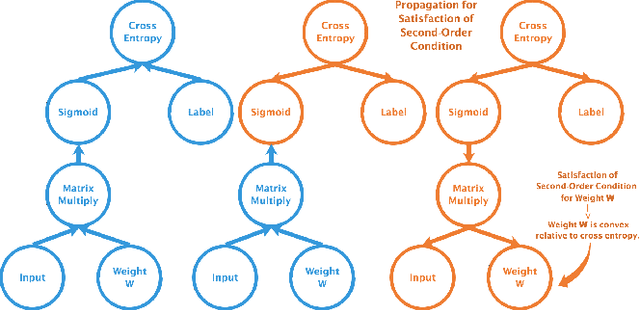
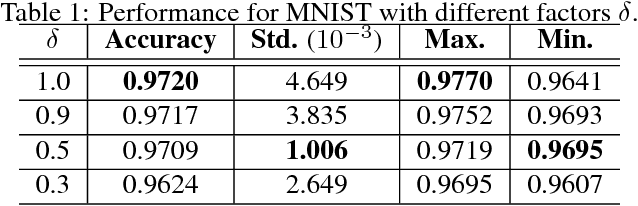
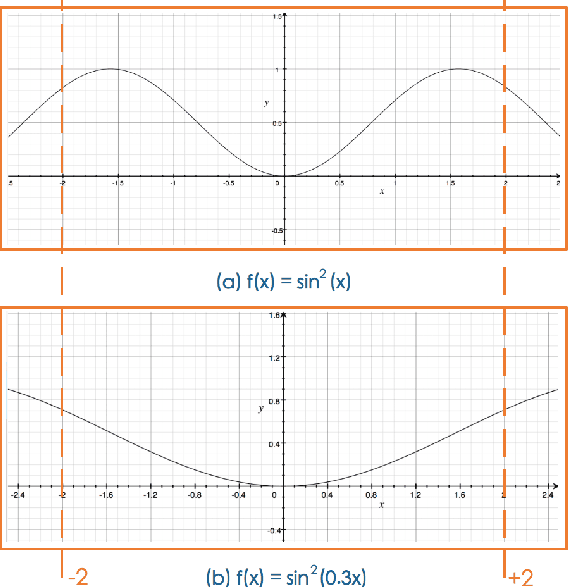
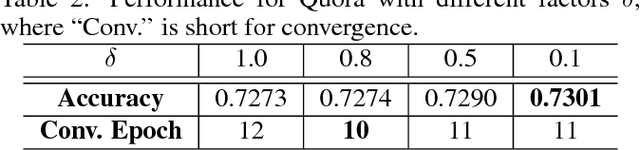
Traditionally, most complex intelligence architectures are extremely non-convex, which could not be well performed by convex optimization. However, this paper decomposes complex structures into three types of nodes: operators, algorithms and functions. Iteratively, propagating from node to node along edge, we prove that "regarding the tree-structured neural graph, it is nearly convex in each variable, when the other variables are fixed." In fact, the non-convex properties stem from circles and functions, which could be transformed to be convex with our proposed \textit{\textbf{scale mechanism}}. Experimentally, we justify our theoretical analysis by two practical applications.
View paper on