 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrue Asymptotic Natural Gradient Optimization
Paper and Code
Dec 22, 2017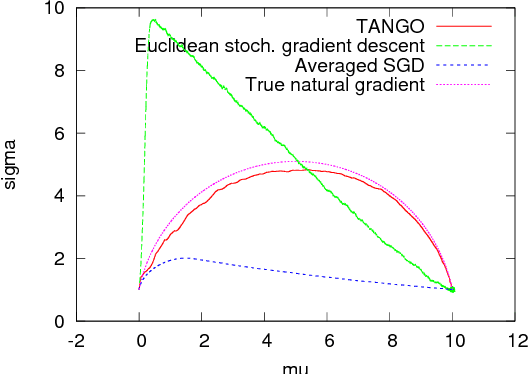
We introduce a simple algorithm, True Asymptotic Natural Gradient Optimization (TANGO), that converges to a true natural gradient descent in the limit of small learning rates, without explicit Fisher matrix estimation. For quadratic models the algorithm is also an instance of averaged stochastic gradient, where the parameter is a moving average of a "fast", constant-rate gradient descent. TANGO appears as a particular de-linearization of averaged SGD, and is sometimes quite different on non-quadratic models. This further connects averaged SGD and natural gradient, both of which are arguably optimal asymptotically. In large dimension, small learning rates will be required to approximate the natural gradient well. Still, this shows it is possible to get arbitrarily close to exact natural gradient descent with a lightweight algorithm.