 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action Recognition: Pose-based Attention draws focus to Hands
Paper and Code
Dec 20, 2017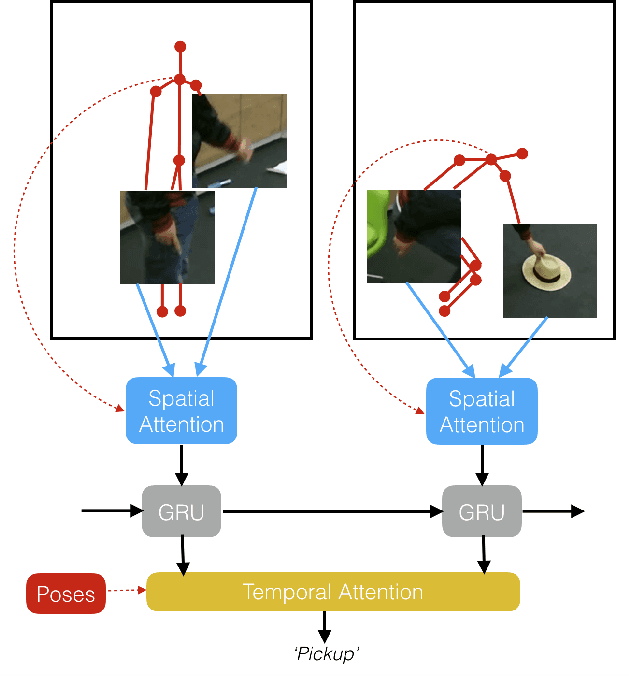
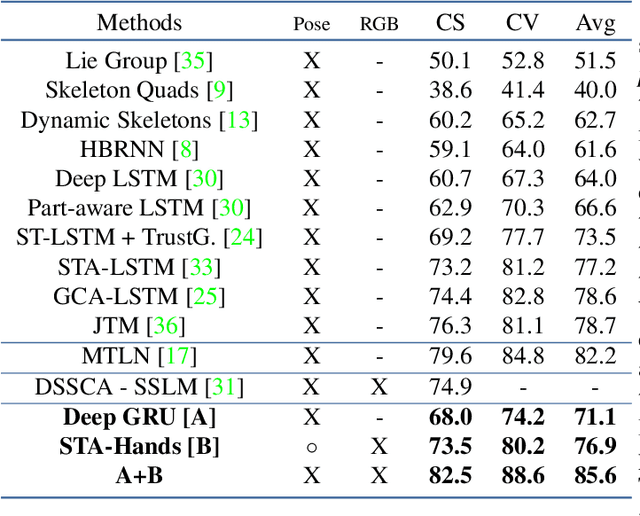
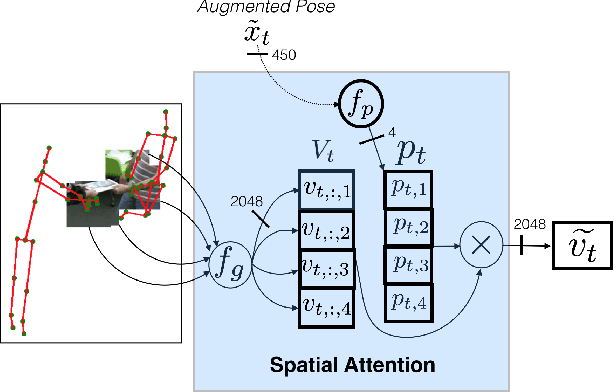
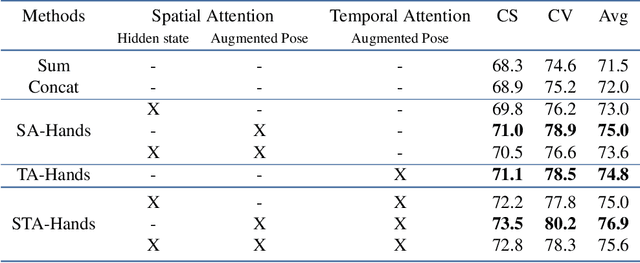
We propose a new spatio-temporal attention based mechanism for human action recognition able to automatically attend to the hands most involved into the studied action and detect the most discriminative moments in an action. Attention is handled in a recurrent manner employing Recurrent Neural Network (RNN) and is fully-differentiable. In contrast to standard soft-attention based mechanisms, our approach does not use the hidden RNN state as input to the attention model. Instead, attention distributions are extracted using external information: human articulated pose. We performed an extensive ablation study to show the strengths of this approach and we particularly studied the conditioning aspect of the attention mechanism. We evaluate the method on the largest currently available human action recognition dataset, NTU-RGB+D, and report state-of-the-art results. Other advantages of our model are certain aspects of explanability, as the spatial and temporal attention distributions at test time allow to study and verify on which parts of the input data the method focuses.