 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock-diagonal Hessian-free Optimization for Training Neural Networks
Paper and Code
Dec 20, 2017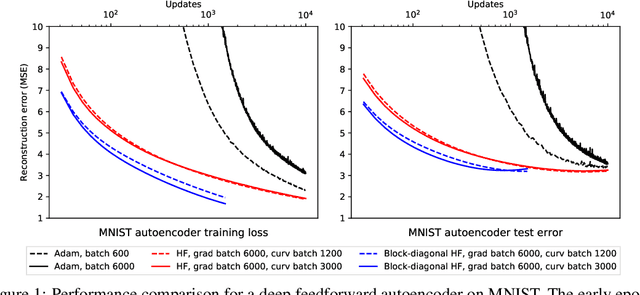
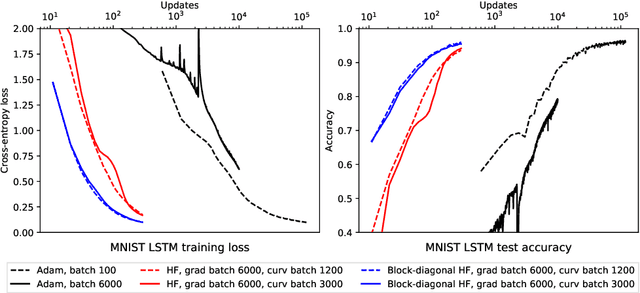
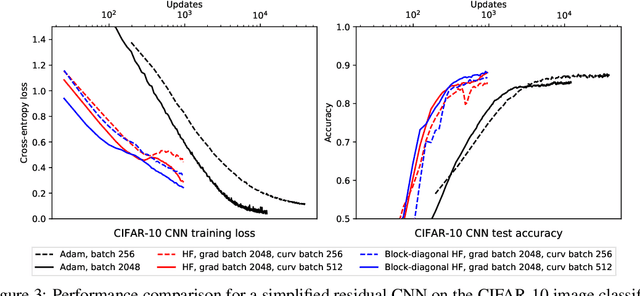
Second-order methods for neural network optimization have several advantages over methods based on first-order gradient descent, including better scaling to large mini-batch sizes and fewer updates needed for convergence. But they are rarely applied to deep learning in practice because of high computational cost and the need for model-dependent algorithmic variations. We introduce a variant of the Hessian-free method that leverages a block-diagonal approximation of the generalized Gauss-Newton matrix. Our method computes the curvature approximation matrix only for pairs of parameters from the same layer or block of the neural network and performs conjugate gradient updates independently for each block. Experiments on deep autoencoders, deep convolutional networks, and multilayer LSTMs demonstrate better convergence and generalization compared to the original Hessian-free approach and the Adam method.