 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Object Detection with an Aligned Spatial-Temporal Memory
Paper and Code
Jul 27, 2018

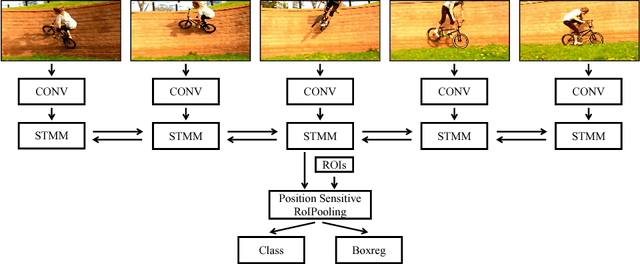

We introduce Spatial-Temporal Memory Networks for video object detection. At its core, a novel Spatial-Temporal Memory module (STMM) serves as the recurrent computation unit to model long-term temporal appearance and motion dynamics. The STMM's design enables full integration of pretrained backbone CNN weights, which we find to be critical for accurate detection. Furthermore, in order to tackle object motion in videos, we propose a novel MatchTrans module to align the spatial-temporal memory from frame to frame. Our method produces state-of-the-art results on the benchmark ImageNet VID dataset, and our ablative studies clearly demonstrate the contribution of our different design choices. We release our code and models at http://fanyix.cs.ucdavis.edu/project/stmn/project.html.