 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Explanation by Interpretation: Improving Visual Feedback Capabilities of Deep Neural Networks
Paper and Code
May 22, 2018
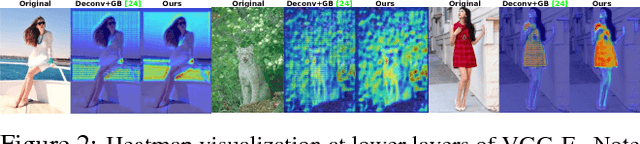
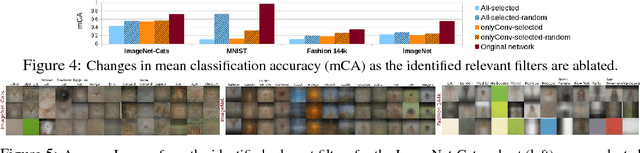

Learning-based representations have become the de facto means to address computer vision tasks. Despite their massive adoption, the amount of work aiming at understanding the internal representations learned by these models is rather limited. Existing methods for model interpretation either require exhaustive manual inspection of visualizations, or link internal network activations with external "possibly useful" annotated concepts. In this paper, we propose an intermediate scheme in which, given a pretrained model, we automatically identify internal features relevant for the set of classes considered by the model, without requiring additional annotations. We interpret the model through average visualizations of these features. Then, at test time, we explain the network prediction by accompanying the predicted class label with supporting heatmap visualizations derived from the identified relevant features. In addition, we propose a method to address the artifacts introduced by strided operations in deconvnet-based visualizations. Moreover, we introduce an8Flower, a dataset specifically designed for the qualitative and quantitative evaluation of methods for model explanation. Our evaluation on the MNIST, ILSVRC12, Fashion144k and an8Flower datasets shows that the proposed method is able to identify relevant internal features for the classes of interest while improving the quality of the produced visualizations.