 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Verification of Machine Learning: The Case of Computer Vision Systems
Paper and Code


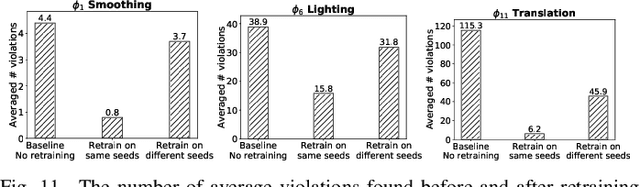
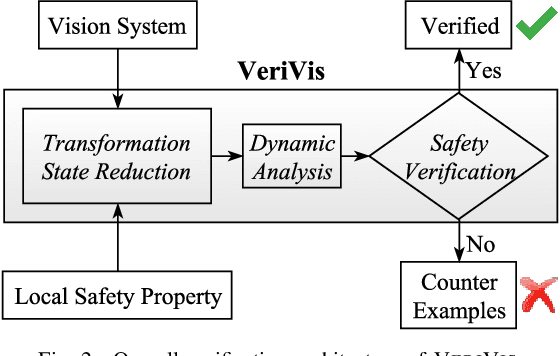
Due to the increasing usage of machine learning (ML) techniques in security- and safety-critical domains, such as autonomous systems and medical diagnosis, ensuring correct behavior of ML systems, especially for different corner cases, is of growing importance. In this paper, we propose a generic framework for evaluating security and robustness of ML systems using different real-world safety properties. We further design, implement and evaluate VeriVis, a scalable methodology that can verify a diverse set of safety properties for state-of-the-art computer vision systems with only blackbox access. VeriVis leverage different input space reduction techniques for efficient verification of different safety properties. VeriVis is able to find thousands of safety violations in fifteen state-of-the-art computer vision systems including ten Deep Neural Networks (DNNs) such as Inception-v3 and Nvidia's Dave self-driving system with thousands of neurons as well as five commercial third-party vision APIs including Google vision and Clarifai for twelve different safety properties. Furthermore, VeriVis can successfully verify local safety properties, on average, for around 31.7% of the test images. VeriVis finds up to 64.8x more violations than existing gradient-based methods that, unlike VeriVis, cannot ensure non-existence of any violations. Finally, we show that retraining using the safety violations detected by VeriVis can reduce the average number of violations up to 60.2%.