 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Less is More - 6D Camera Localization via 3D Surface Regression
Paper and Code
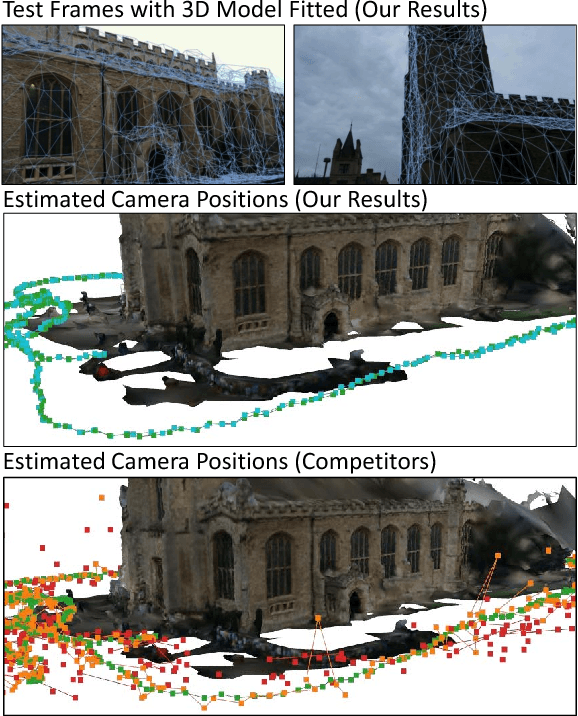
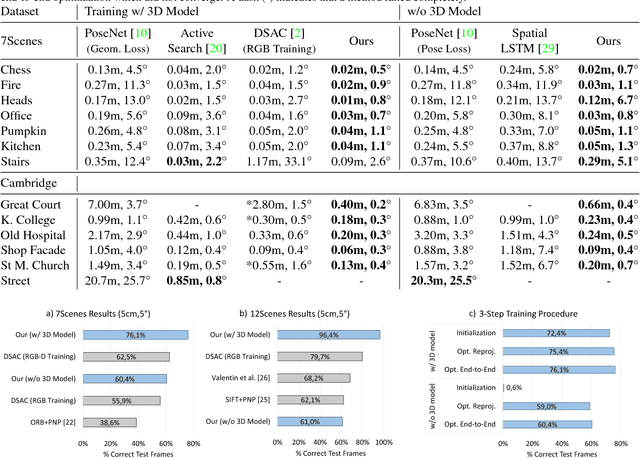
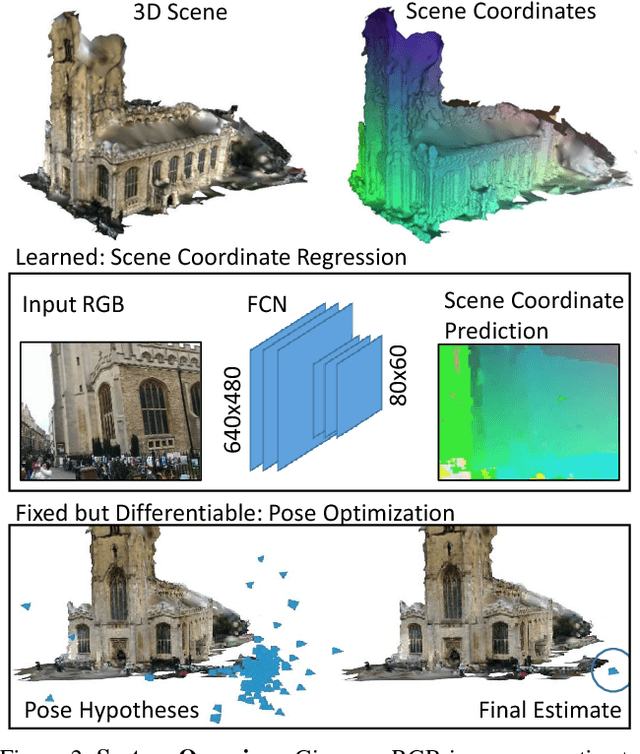

Popular research areas like autonomous driving and augmented reality have renewed the interest in image-based camera localization. In this work, we address the task of predicting the 6D camera pose from a single RGB image in a given 3D environment. With the advent of neural networks, previous works have either learned the entire camera localization process, or multiple components of a camera localization pipeline. Our key contribution is to demonstrate and explain that learning a single component of this pipeline is sufficient. This component is a fully convolutional neural network for densely regressing so-called scene coordinates, defining the correspondence between the input image and the 3D scene space. The neural network is prepended to a new end-to-end trainable pipeline. Our system is efficient, highly accurate, robust in training, and exhibits outstanding generalization capabilities. It exceeds state-of-the-art consistently on indoor and outdoor datasets. Interestingly, our approach surpasses existing techniques even without utilizing a 3D model of the scene during training, since the network is able to discover 3D scene geometry automatically, solely from single-view constraints.