 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients
Paper and Code
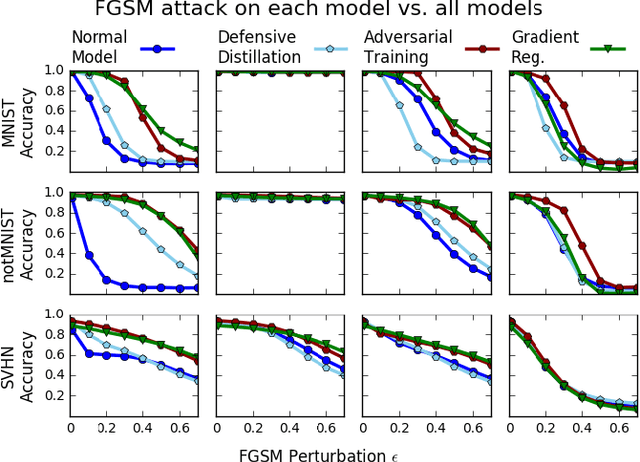

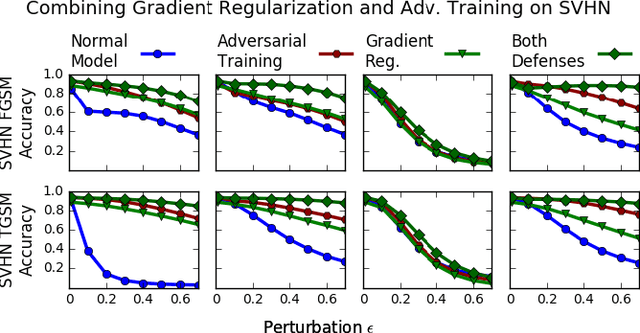
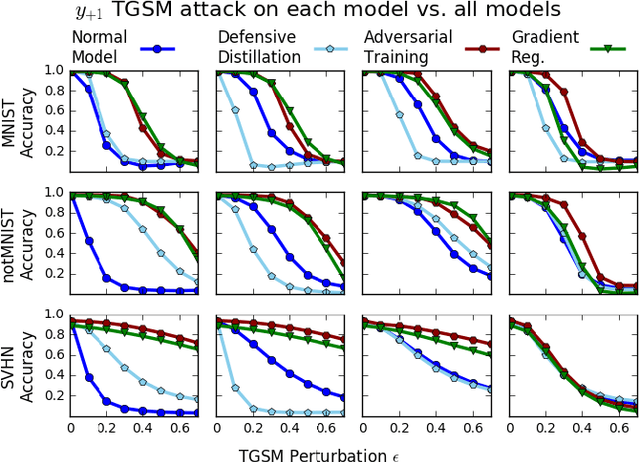
Deep neural networks have proven remarkably effective at solving many classification problems, but have been criticized recently for two major weaknesses: the reasons behind their predictions are uninterpretable, and the predictions themselves can often be fooled by small adversarial perturbations. These problems pose major obstacles for the adoption of neural networks in domains that require security or transparency. In this work, we evaluate the effectiveness of defenses that differentiably penalize the degree to which small changes in inputs can alter model predictions. Across multiple attacks, architectures, defenses, and datasets, we find that neural networks trained with this input gradient regularization exhibit robustness to transferred adversarial examples generated to fool all of the other models. We also find that adversarial examples generated to fool gradient-regularized models fool all other models equally well, and actually lead to more "legitimate," interpretable misclassifications as rated by people (which we confirm in a human subject experiment). Finally, we demonstrate that regularizing input gradients makes them more naturally interpretable as rationales for model predictions. We conclude by discussing this relationship between interpretability and robustness in deep neural networks.