 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn2I : Unsupervised Multi-Image-to-Image Translation Using Generative Adversarial Networks
Paper and Code
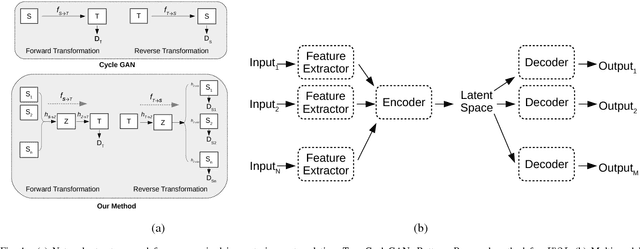
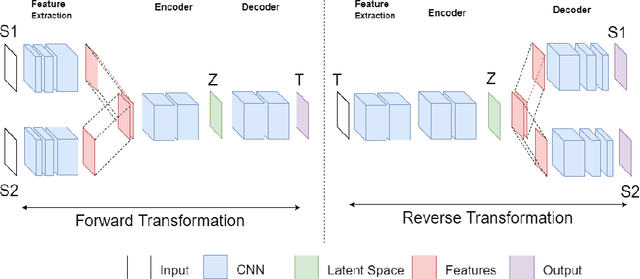


In unsupervised image-to-image translation, the goal is to learn the mapping between an input image and an output image using a set of unpaired training images. In this paper, we propose an extension of the unsupervised image-to-image translation problem to multiple input setting. Given a set of paired images from multiple modalities, a transformation is learned to translate the input into a specified domain. For this purpose, we introduce a Generative Adversarial Network (GAN) based framework along with a multi-modal generator structure and a new loss term, latent consistency loss. Through various experiments we show that leveraging multiple inputs generally improves the visual quality of the translated images. Moreover, we show that the proposed method outperforms current state-of-the-art unsupervised image-to-image translation methods.