 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Learning via Class-Conditioned Deep Generative Models
Paper and Code
Nov 19, 2017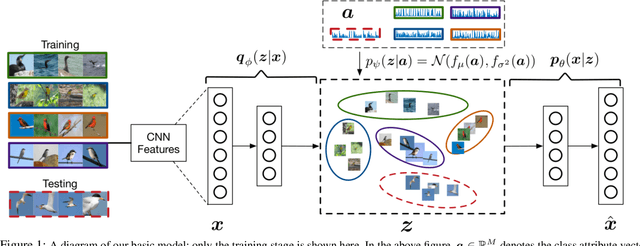
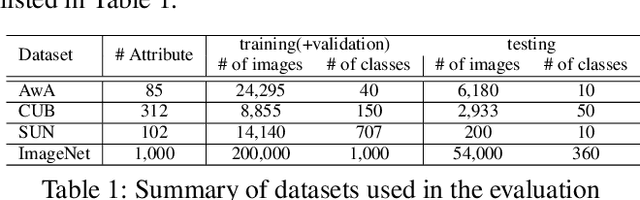
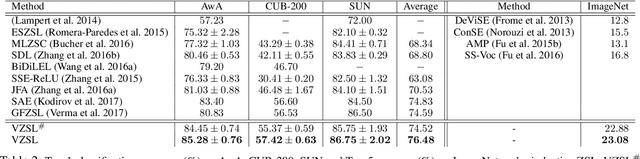
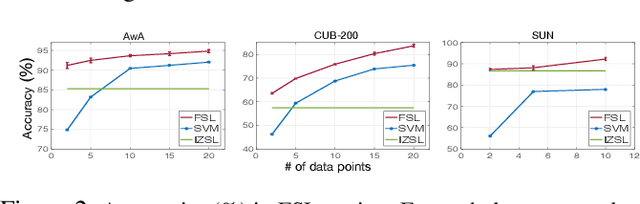
We present a deep generative model for learning to predict classes not seen at training time. Unlike most existing methods for this problem, that represent each class as a point (via a semantic embedding), we represent each seen/unseen class using a class-specific latent-space distribution, conditioned on class attributes. We use these latent-space distributions as a prior for a supervised variational autoencoder (VAE), which also facilitates learning highly discriminative feature representations for the inputs. The entire framework is learned end-to-end using only the seen-class training data. The model infers corresponding attributes of a test image by maximizing the VAE lower bound; the inferred attributes may be linked to labels not seen when training. We further extend our model to a (1) semi-supervised/transductive setting by leveraging unlabeled unseen-class data via an unsupervised learning module, and (2) few-shot learning where we also have a small number of labeled inputs from the unseen classes. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of benchmark data sets.