 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming data scarcity with transfer learning
Paper and Code
Nov 02, 2017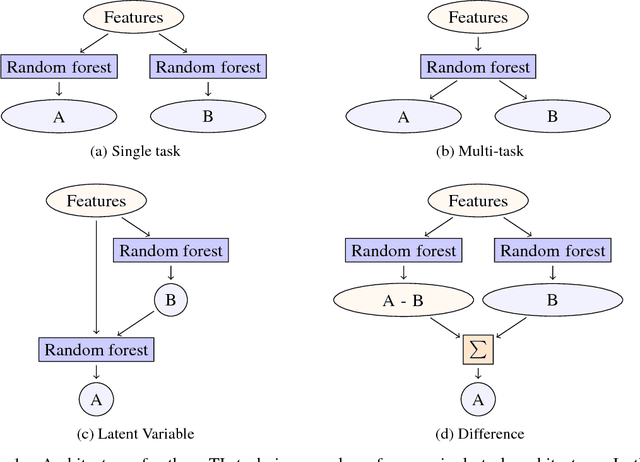
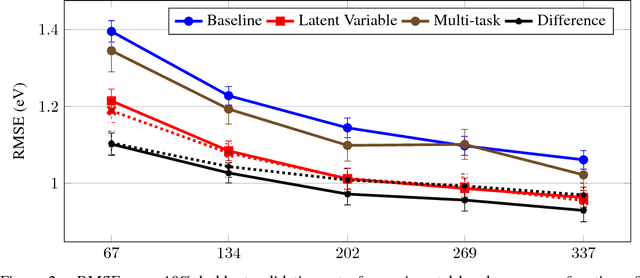
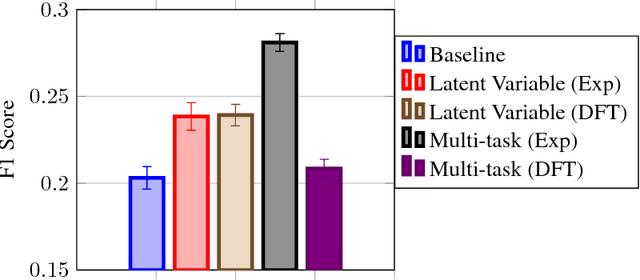
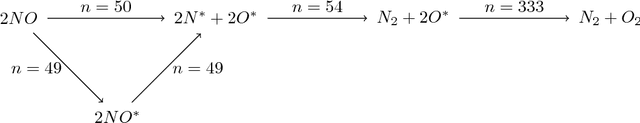
Despite increasing focus on data publication and discovery in materials science and related fields, the global view of materials data is highly sparse. This sparsity encourages training models on the union of multiple datasets, but simple unions can prove problematic as (ostensibly) equivalent properties may be measured or computed differently depending on the data source. These hidden contextual differences introduce irreducible errors into analyses, fundamentally limiting their accuracy. Transfer learning, where information from one dataset is used to inform a model on another, can be an effective tool for bridging sparse data while preserving the contextual differences in the underlying measurements. Here, we describe and compare three techniques for transfer learning: multi-task, difference, and explicit latent variable architectures. We show that difference architectures are most accurate in the multi-fidelity case of mixed DFT and experimental band gaps, while multi-task most improves classification performance of color with band gaps. For activation energies of steps in NO reduction, the explicit latent variable method is not only the most accurate, but also enjoys cancellation of errors in functions that depend on multiple tasks. These results motivate the publication of high quality materials datasets that encode transferable information, independent of industrial or academic interest in the particular labels, and encourage further development and application of transfer learning methods to materials informatics problems.