 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical Structured Prediction Losses for Sequence to Sequence Learning
Paper and Code
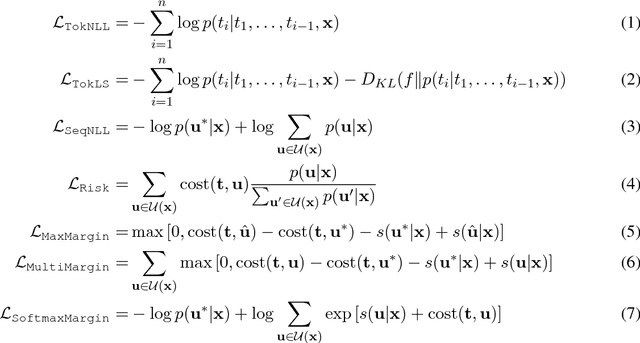
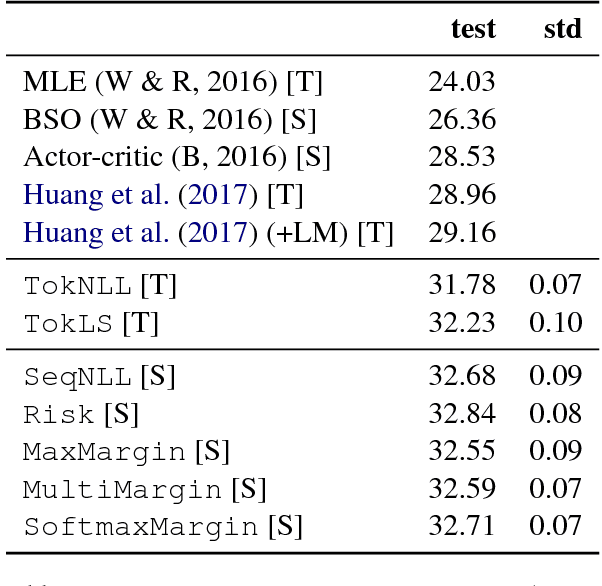
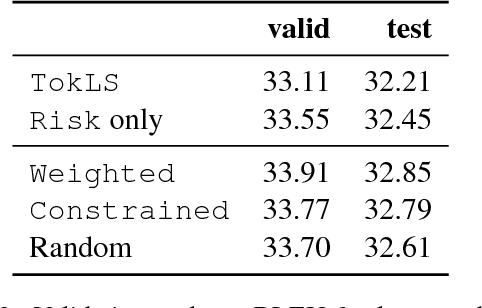
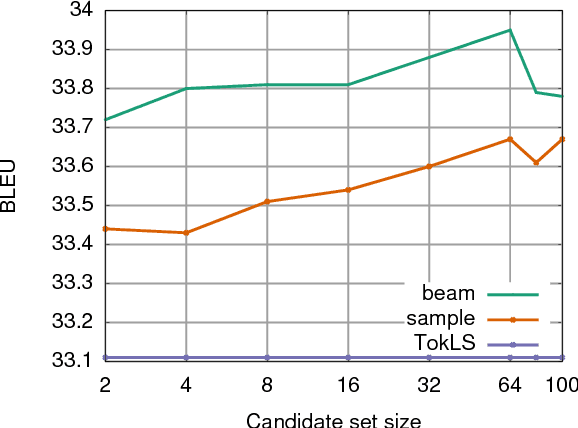
There has been much recent work on training neural attention models at the sequence-level using either reinforcement learning-style methods or by optimizing the beam. In this paper, we survey a range of classical objective functions that have been widely used to train linear models for structured prediction and apply them to neural sequence to sequence models. Our experiments show that these losses can perform surprisingly well by slightly outperforming beam search optimization in a like for like setup. We also report new state of the art results on both IWSLT'14 German-English translation as well as Gigaword abstractive summarization. On the larger WMT'14 English-French translation task, sequence-level training achieves 41.5 BLEU which is on par with the state of the art.