 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Options that Terminate Off-Policy
Paper and Code
Dec 02, 2017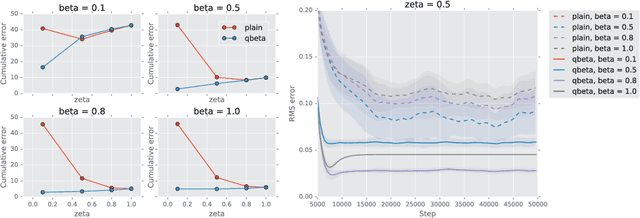
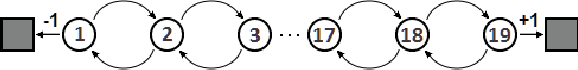
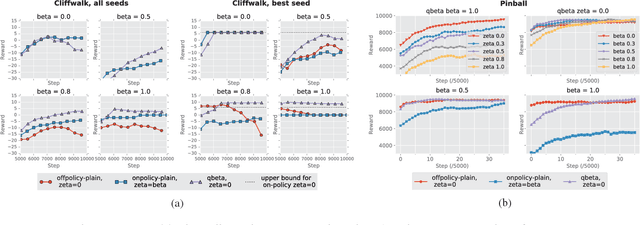
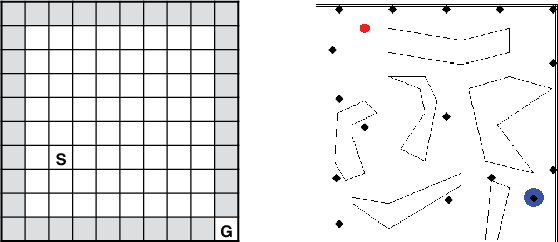
A temporally abstract action, or an option, is specified by a policy and a termination condition: the policy guides option behavior, and the termination condition roughly determines its length. Generally, learning with longer options (like learning with multi-step returns) is known to be more efficient. However, if the option set for the task is not ideal, and cannot express the primitive optimal policy exactly, shorter options offer more flexibility and can yield a better solution. Thus, the termination condition puts learning efficiency at odds with solution quality. We propose to resolve this dilemma by decoupling the behavior and target terminations, just like it is done with policies in off-policy learning. To this end, we give a new algorithm, Q(\beta), that learns the solution with respect to any termination condition, regardless of how the options actually terminate. We derive Q(\beta) by casting learning with options into a common framework with well-studied multi-step off-policy learning. We validate our algorithm empirically, and show that it holds up to its motivating claims.