 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Non-overlapping Convolutional Neural Networks with Multiple Kernels
Paper and Code
Nov 08, 2017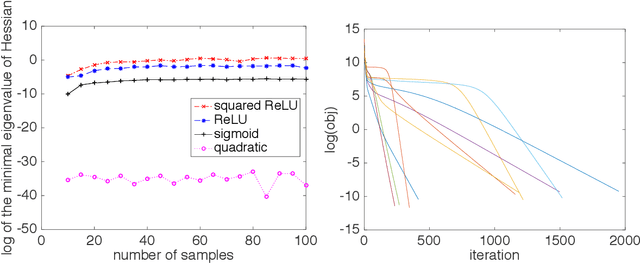

In this paper, we consider parameter recovery for non-overlapping convolutional neural networks (CNNs) with multiple kernels. We show that when the inputs follow Gaussian distribution and the sample size is sufficiently large, the squared loss of such CNNs is $\mathit{~locally~strongly~convex}$ in a basin of attraction near the global optima for most popular activation functions, like ReLU, Leaky ReLU, Squared ReLU, Sigmoid and Tanh. The required sample complexity is proportional to the dimension of the input and polynomial in the number of kernels and a condition number of the parameters. We also show that tensor methods are able to initialize the parameters to the local strong convex region. Hence, for most smooth activations, gradient descent following tensor initialization is guaranteed to converge to the global optimal with time that is linear in input dimension, logarithmic in precision and polynomial in other factors. To the best of our knowledge, this is the first work that provides recovery guarantees for CNNs with multiple kernels under polynomial sample and computational complexities.