 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks
Paper and Code

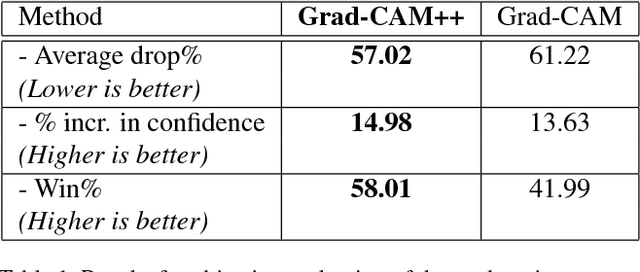
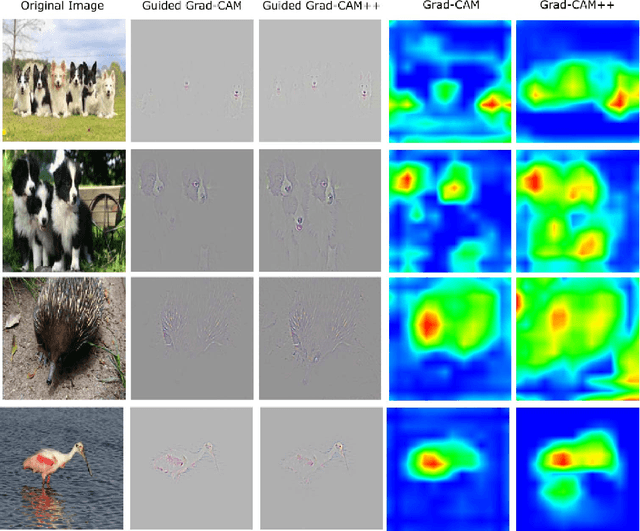
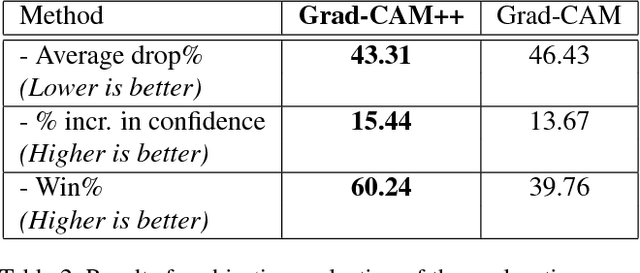
Over the last decade, Convolutional Neural Network (CNN) models have been highly successful in solving complex vision based problems. However, these deep models are perceived as "black box" methods considering the lack of understanding of their internal functioning. There has been a significant recent interest to develop explainable deep learning models, and this paper is an effort in this direction. Building on a recently proposed method called Grad-CAM, we propose a generalized method called Grad-CAM++ that can provide better visual explanations of CNN model predictions, in terms of better object localization as well as explaining occurrences of multiple object instances in a single image, when compared to state-of-the-art. We provide a mathematical derivation for the proposed method, which uses a weighted combination of the positive partial derivatives of the last convolutional layer feature maps with respect to a specific class score as weights to generate a visual explanation for the corresponding class label. Our extensive experiments and evaluations, both subjective and objective, on standard datasets showed that Grad-CAM++ provides promising human-interpretable visual explanations for a given CNN architecture across multiple tasks including classification, image caption generation and 3D action recognition; as well as in new settings such as knowledge distillation.