 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Avoiding Optimization Methods for Distributed Massive-Scale Sparse Inverse Covariance Estimation
Paper and Code
Apr 08, 2018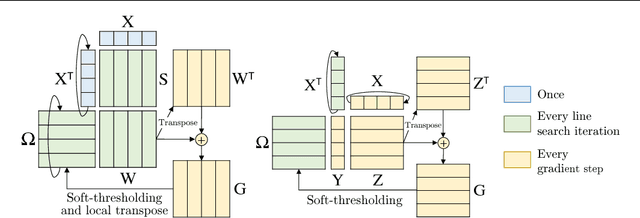
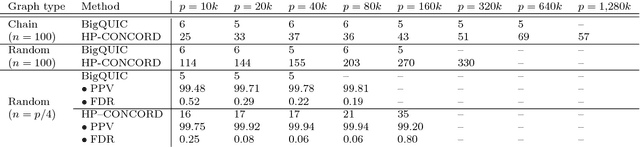
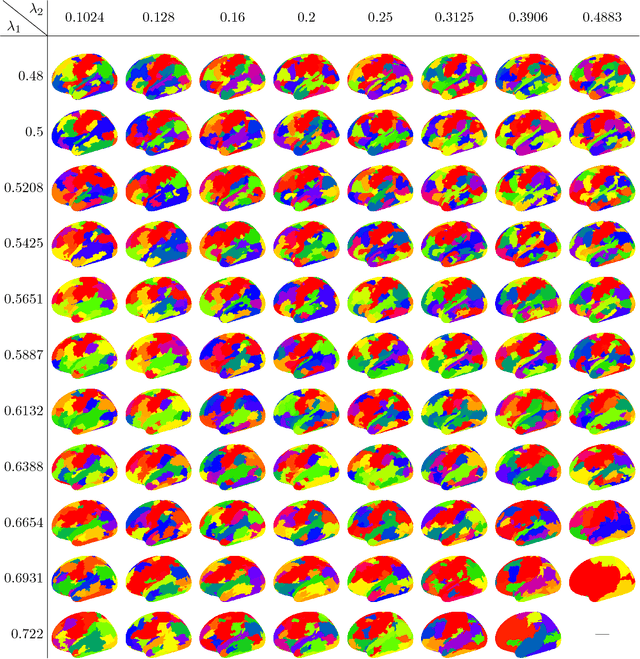
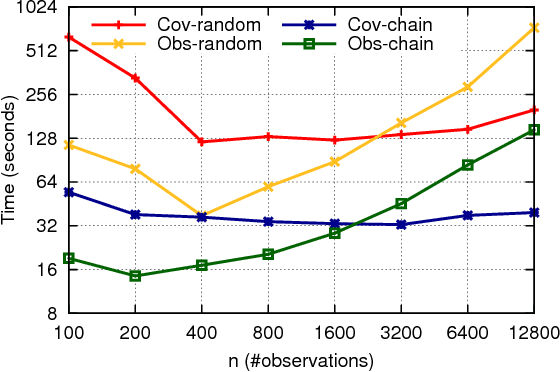
Across a variety of scientific disciplines, sparse inverse covariance estimation is a popular tool for capturing the underlying dependency relationships in multivariate data. Unfortunately, most estimators are not scalable enough to handle the sizes of modern high-dimensional data sets (often on the order of terabytes), and assume Gaussian samples. To address these deficiencies, we introduce HP-CONCORD, a highly scalable optimization method for estimating a sparse inverse covariance matrix based on a regularized pseudolikelihood framework, without assuming Gaussianity. Our parallel proximal gradient method uses a novel communication-avoiding linear algebra algorithm and runs across a multi-node cluster with up to 1k nodes (24k cores), achieving parallel scalability on problems with up to ~819 billion parameters (1.28 million dimensions); even on a single node, HP-CONCORD demonstrates scalability, outperforming a state-of-the-art method. We also use HP-CONCORD to estimate the underlying dependency structure of the brain from fMRI data, and use the result to identify functional regions automatically. The results show good agreement with a clustering from the neuroscience literature.