 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Label Embedding for Text Classification
Paper and Code
Oct 17, 2017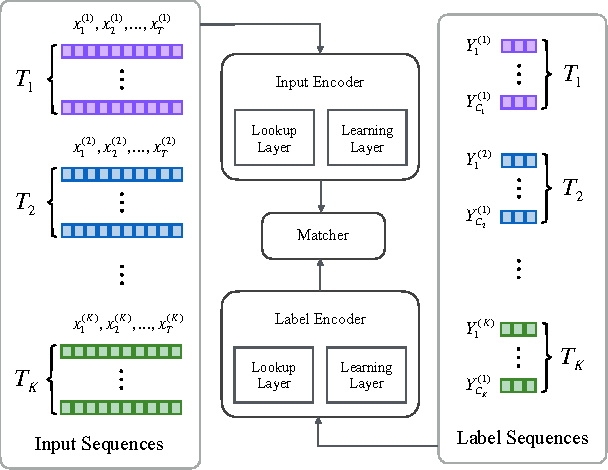
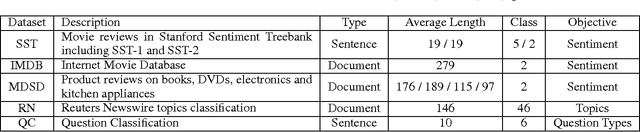
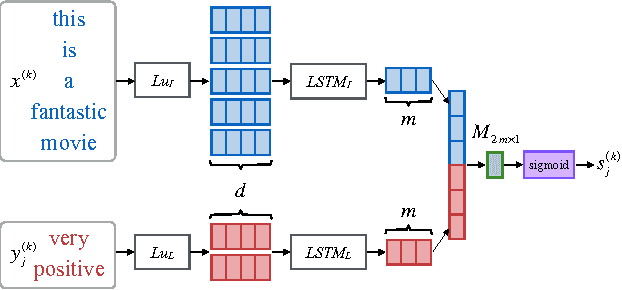

Multi-task learning in text classification leverages implicit correlations among related tasks to extract common features and yield performance gains. However, most previous works treat labels of each task as independent and meaningless one-hot vectors, which cause a loss of potential information and makes it difficult for these models to jointly learn three or more tasks. In this paper, we propose Multi-Task Label Embedding to convert labels in text classification into semantic vectors, thereby turning the original tasks into vector matching tasks. We implement unsupervised, supervised and semi-supervised models of Multi-Task Label Embedding, all utilizing semantic correlations among tasks and making it particularly convenient to scale and transfer as more tasks are involved. Extensive experiments on five benchmark datasets for text classification show that our models can effectively improve performances of related tasks with semantic representations of labels and additional information from each other.