 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking and Selection with Covariates for Personalized Decision Making
Paper and Code
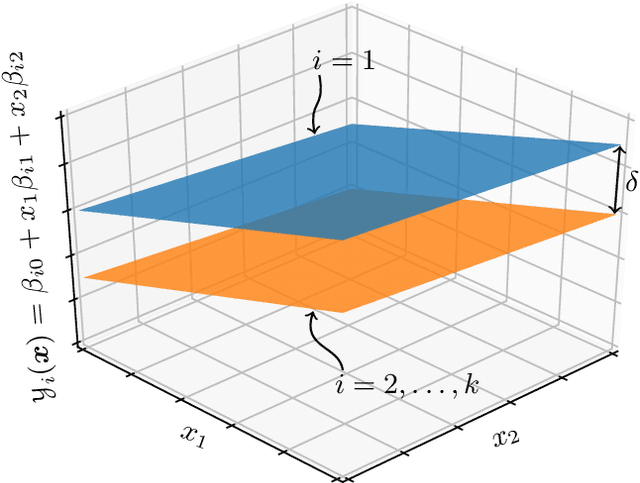
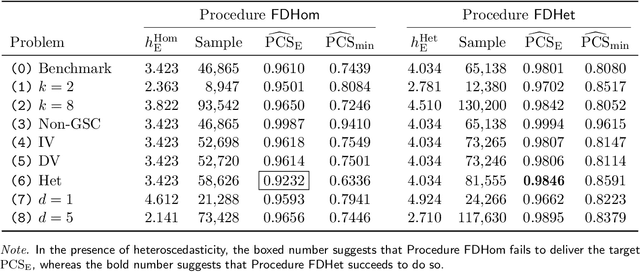
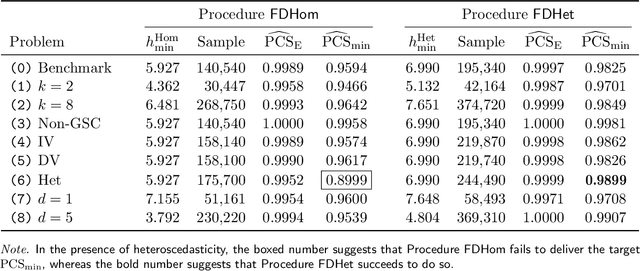
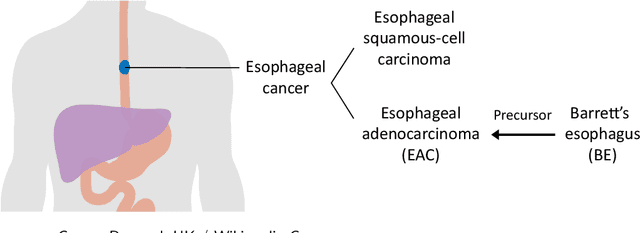
We consider a ranking and selection problem in the context of personalized decision making, where the best alternative is not universal but varies as a function of observable covariates. The goal of ranking and selection with covariates (R&S-C) is to use sampling to compute a decision rule that can specify the best alternative with certain statistical guarantee for each subsequent individual after observing his or her covariates. A linear model is proposed to capture the relationship between the mean performance of an alternative and the covariates. Under the indifference-zone formulation, we develop two-stage procedures for both homoscedastic and heteroscedastic sampling errors, respectively, and prove their statistical validity, which is defined in terms of probability of correct selection. We also generalize the well-known slippage configuration, and prove that the generalized slippage configuration is the least favorable configuration of our procedures. Extensive numerical experiments are conducted to investigate the performance of the proposed procedures. Finally, we demonstrate the usefulness of R&S-C via a case study of selecting the best treatment regimen in the prevention of esophageal cancer. We find that by leveraging disease-related personal information, R&S-C can improve substantially the expected quality-adjusted life years for some groups of patients through providing patient-specific treatment regimen.