 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Construction via Attention for Aspect Term Extraction with Distant Supervision
Paper and Code
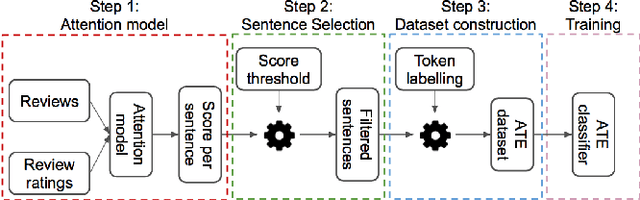
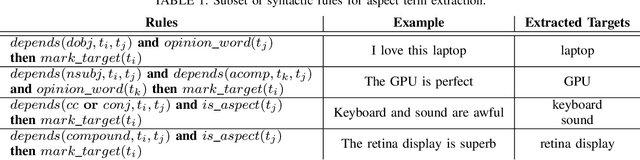
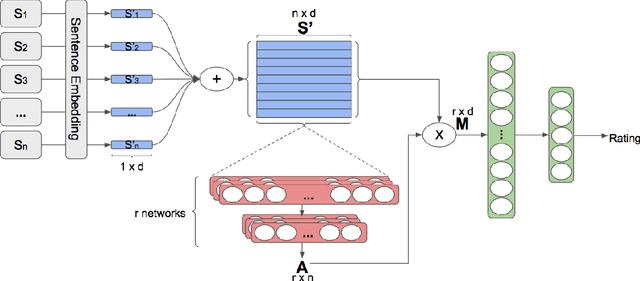
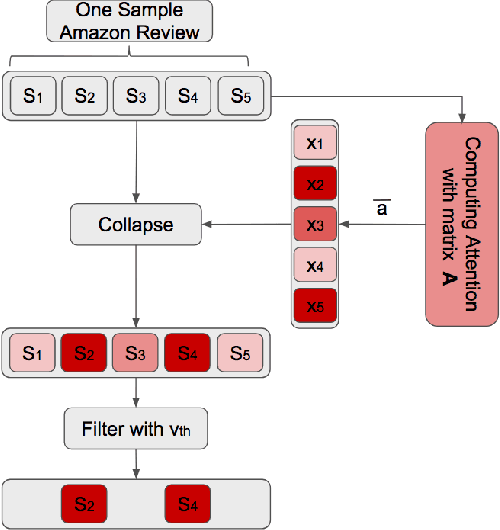
Aspect Term Extraction (ATE) detects opinionated aspect terms in sentences or text spans, with the end goal of performing aspect-based sentiment analysis. The small amount of available datasets for supervised ATE and the fact that they cover only a few domains raise the need for exploiting other data sources in new and creative ways. Publicly available review corpora contain a plethora of opinionated aspect terms and cover a larger domain spectrum. In this paper, we first propose a method for using such review corpora for creating a new dataset for ATE. Our method relies on an attention mechanism to select sentences that have a high likelihood of containing actual opinionated aspects. We thus improve the quality of the extracted aspects. We then use the constructed dataset to train a model and perform ATE with distant supervision. By evaluating on human annotated datasets, we prove that our method achieves a significantly improved performance over various unsupervised and supervised baselines. Finally, we prove that sentence selection matters when it comes to creating new datasets for ATE. Specifically, we show that, using a set of selected sentences leads to higher ATE performance compared to using the whole sentence set.