 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEZLearn: Exploiting Organic Supervision in Large-Scale Data Annotation
Paper and Code
Jul 02, 2018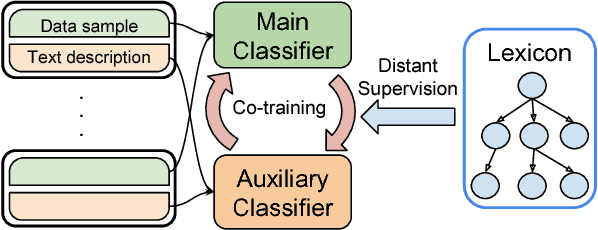


Many real-world applications require automated data annotation, such as identifying tissue origins based on gene expressions and classifying images into semantic categories. Annotation classes are often numerous and subject to changes over time, and annotating examples has become the major bottleneck for supervised learning methods. In science and other high-value domains, large repositories of data samples are often available, together with two sources of organic supervision: a lexicon for the annotation classes, and text descriptions that accompany some data samples. Distant supervision has emerged as a promising paradigm for exploiting such indirect supervision by automatically annotating examples where the text description contains a class mention in the lexicon. However, due to linguistic variations and ambiguities, such training data is inherently noisy, which limits the accuracy of this approach. In this paper, we introduce an auxiliary natural language processing system for the text modality, and incorporate co-training to reduce noise and augment signal in distant supervision. Without using any manually labeled data, our EZLearn system learned to accurately annotate data samples in functional genomics and scientific figure comprehension, substantially outperforming state-of-the-art supervised methods trained on tens of thousands of annotated examples.