 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Dictionaries for Zero-Shot Learning
Paper and Code
Sep 12, 2017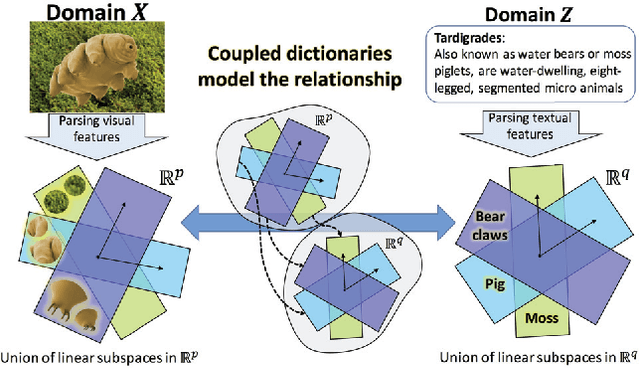
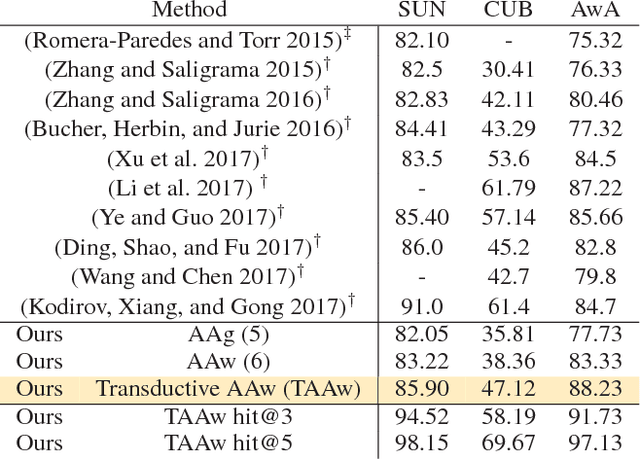
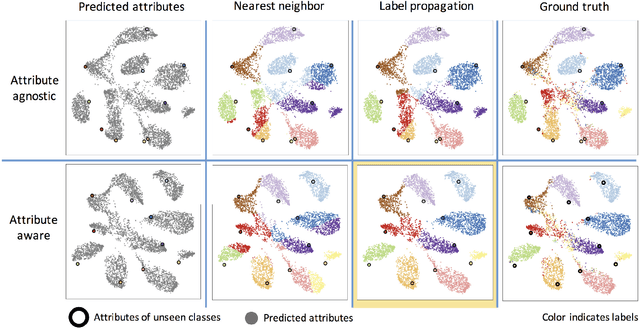
A classic approach toward zero-shot learning (ZSL) is to map the input domain to a set of semantically meaningful attributes that could be used later on to classify unseen classes of data (e.g. visual data). In this paper, we propose to learn a visual feature dictionary that has semantically meaningful atoms. Such dictionary is learned via joint dictionary learning for the visual domain and the attribute domain, while enforcing the same sparse coding for both dictionaries. Our novel attribute aware formulation provides an algorithmic solution to the domain shift/hubness problem in ZSL. Upon learning the joint dictionaries, images from unseen classes can be mapped into the attribute space by finding the attribute aware joint sparse representation using solely the visual data. We demonstrate that our approach provides superior or comparable performance to that of the state of the art on benchmark datasets.