 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTandemNet: Distilling Knowledge from Medical Images Using Diagnostic Reports as Optional Semantic References
Paper and Code
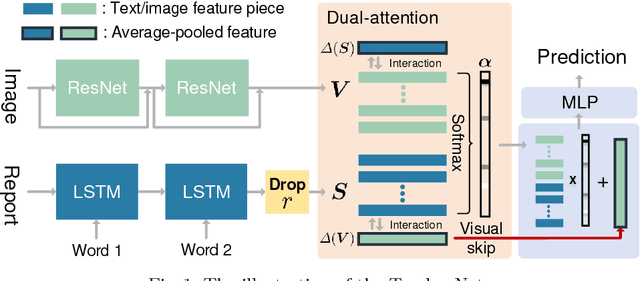

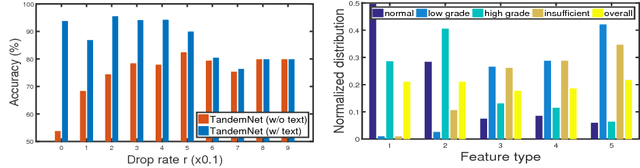
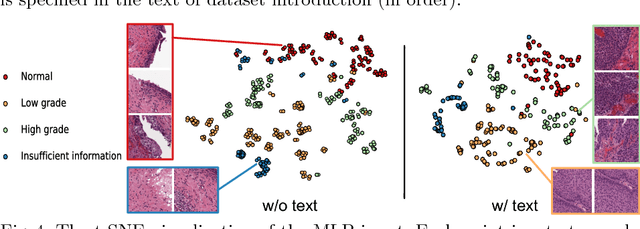
In this paper, we introduce the semantic knowledge of medical images from their diagnostic reports to provide an inspirational network training and an interpretable prediction mechanism with our proposed novel multimodal neural network, namely TandemNet. Inside TandemNet, a language model is used to represent report text, which cooperates with the image model in a tandem scheme. We propose a novel dual-attention model that facilitates high-level interactions between visual and semantic information and effectively distills useful features for prediction. In the testing stage, TandemNet can make accurate image prediction with an optional report text input. It also interprets its prediction by producing attention on the image and text informative feature pieces, and further generating diagnostic report paragraphs. Based on a pathological bladder cancer images and their diagnostic reports (BCIDR) dataset, sufficient experiments demonstrate that our method effectively learns and integrates knowledge from multimodalities and obtains significantly improved performance than comparing baselines.