 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerAI DDL
Paper and Code
Aug 07, 2017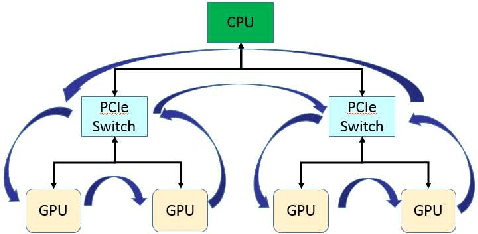
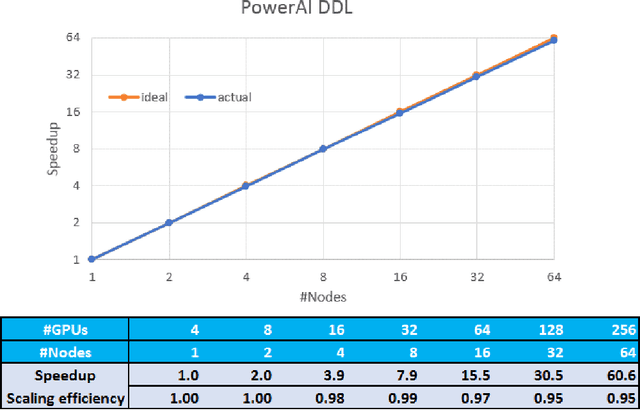
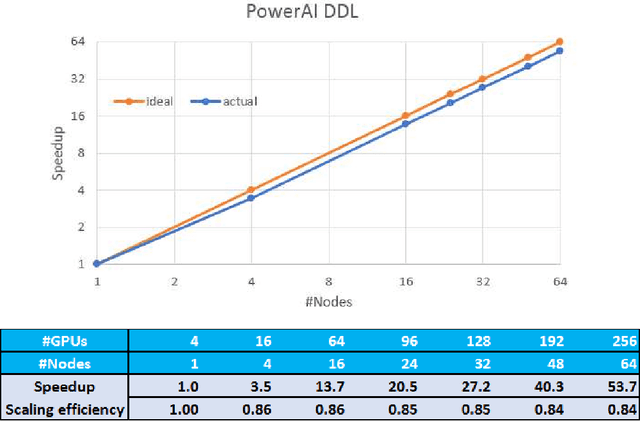
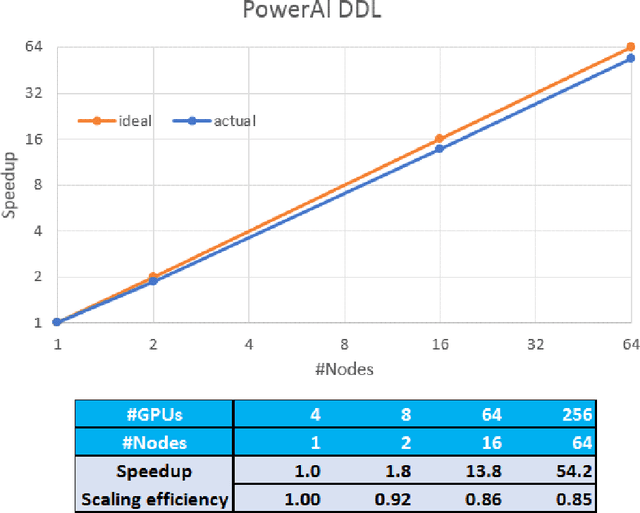
As deep neural networks become more complex and input datasets grow larger, it can take days or even weeks to train a deep neural network to the desired accuracy. Therefore, distributed Deep Learning at a massive scale is a critical capability, since it offers the potential to reduce the training time from weeks to hours. In this paper, we present a software-hardware co-optimized distributed Deep Learning system that can achieve near-linear scaling up to hundreds of GPUs. The core algorithm is a multi-ring communication pattern that provides a good tradeoff between latency and bandwidth and adapts to a variety of system configurations. The communication algorithm is implemented as a library for easy use. This library has been integrated into Tensorflow, Caffe, and Torch. We train Resnet-101 on Imagenet 22K with 64 IBM Power8 S822LC servers (256 GPUs) in about 7 hours to an accuracy of 33.8 % validation accuracy. Microsoft's ADAM and Google's DistBelief results did not reach 30 % validation accuracy for Imagenet 22K. Compared to Facebook AI Research's recent paper on 256 GPU training, we use a different communication algorithm, and our combined software and hardware system offers better communication overhead for Resnet-50. A PowerAI DDL enabled version of Torch completed 90 epochs of training on Resnet 50 for 1K classes in 50 minutes using 64 IBM Power8 S822LC servers (256 GPUs).