 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Clustering Algorithms via Small-Variance Analysis of Markov Chain Mixture Models
Paper and Code
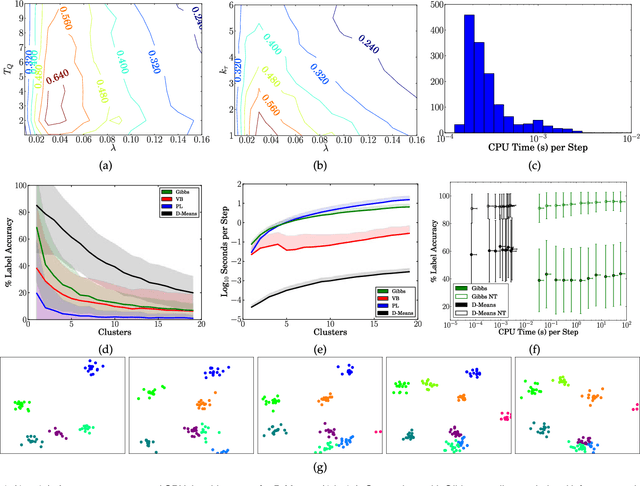

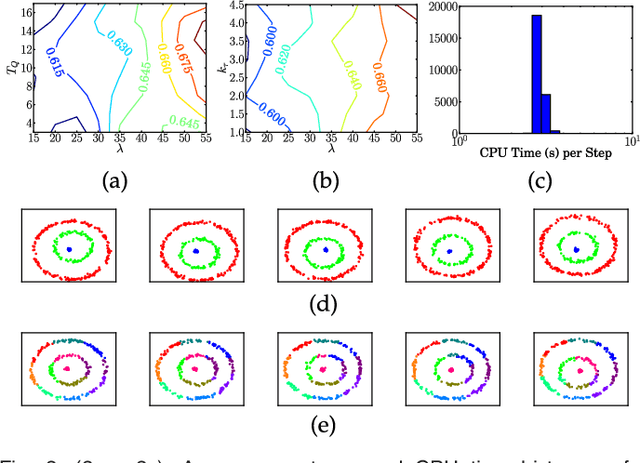
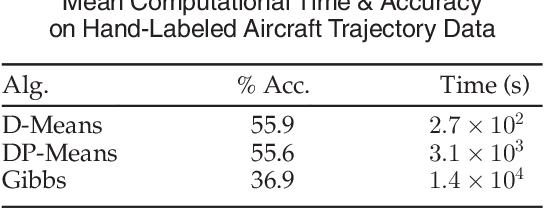
Bayesian nonparametrics are a class of probabilistic models in which the model size is inferred from data. A recently developed methodology in this field is small-variance asymptotic analysis, a mathematical technique for deriving learning algorithms that capture much of the flexibility of Bayesian nonparametric inference algorithms, but are simpler to implement and less computationally expensive. Past work on small-variance analysis of Bayesian nonparametric inference algorithms has exclusively considered batch models trained on a single, static dataset, which are incapable of capturing time evolution in the latent structure of the data. This work presents a small-variance analysis of the maximum a posteriori filtering problem for a temporally varying mixture model with a Markov dependence structure, which captures temporally evolving clusters within a dataset. Two clustering algorithms result from the analysis: D-Means, an iterative clustering algorithm for linearly separable, spherical clusters; and SD-Means, a spectral clustering algorithm derived from a kernelized, relaxed version of the clustering problem. Empirical results from experiments demonstrate the advantages of using D-Means and SD-Means over contemporary clustering algorithms, in terms of both computational cost and clustering accuracy.