 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected exponential loss for gaze-based video and volume ground truth annotation
Paper and Code
Jul 16, 2017
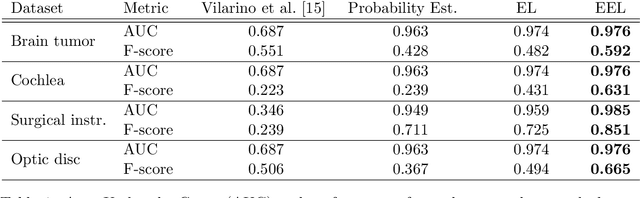
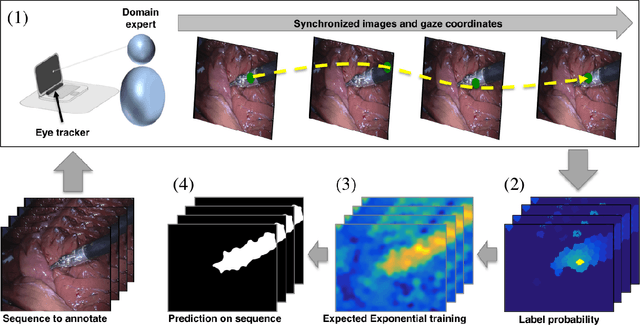

Many recent machine learning approaches used in medical imaging are highly reliant on large amounts of image and ground truth data. In the context of object segmentation, pixel-wise annotations are extremely expensive to collect, especially in video and 3D volumes. To reduce this annotation burden, we propose a novel framework to allow annotators to simply observe the object to segment and record where they have looked at with a \$200 eye gaze tracker. Our method then estimates pixel-wise probabilities for the presence of the object throughout the sequence from which we train a classifier in semi-supervised setting using a novel Expected Exponential loss function. We show that our framework provides superior performances on a wide range of medical image settings compared to existing strategies and that our method can be combined with current crowd-sourcing paradigms as well.