 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in High-Dimensional Multimedia Data: The State of the Art
Paper and Code
Jul 10, 2017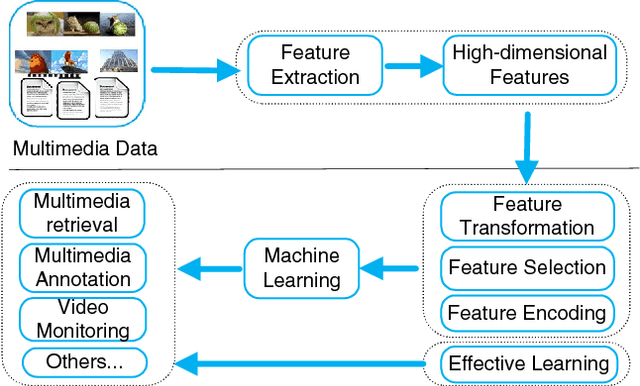
During the last decade, the deluge of multimedia data has impacted a wide range of research areas, including multimedia retrieval, 3D tracking, database management, data mining, machine learning, social media analysis, medical imaging, and so on. Machine learning is largely involved in multimedia applications of building models for classification and regression tasks etc., and the learning principle consists in designing the models based on the information contained in the multimedia dataset. While many paradigms exist and are widely used in the context of machine learning, most of them suffer from the `curse of dimensionality', which means that some strange phenomena appears when data are represented in a high-dimensional space. Given the high dimensionality and the high complexity of multimedia data, it is important to investigate new machine learning algorithms to facilitate multimedia data analysis. To deal with the impact of high dimensionality, an intuitive way is to reduce the dimensionality. On the other hand, some researchers devoted themselves to designing some effective learning schemes for high-dimensional data. In this survey, we cover feature transformation, feature selection and feature encoding, three approaches fighting the consequences of the curse of dimensionality. Next, we briefly introduce some recent progress of effective learning algorithms. Finally, promising future trends on multimedia learning are envisaged.