 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Audio Captioning with Recurrent Neural Networks
Paper and Code
Oct 24, 2017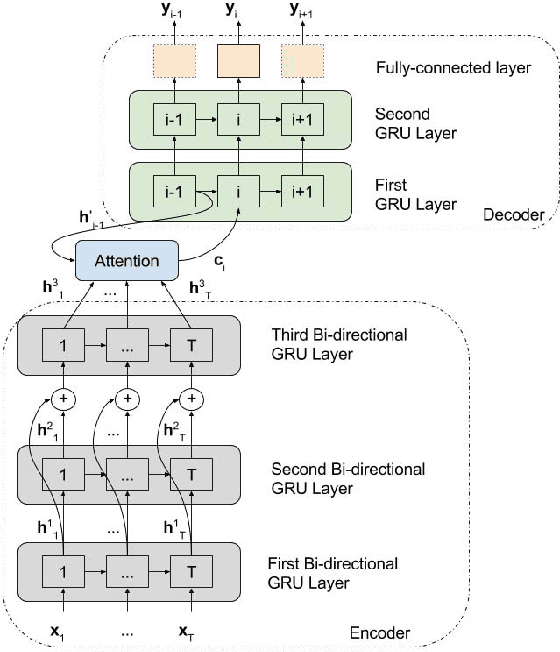
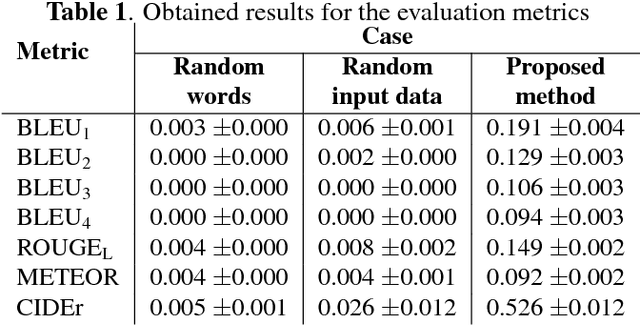
We present the first approach to automated audio captioning. We employ an encoder-decoder scheme with an alignment model in between. The input to the encoder is a sequence of log mel-band energies calculated from an audio file, while the output is a sequence of words, i.e. a caption. The encoder is a multi-layered, bi-directional gated recurrent unit (GRU) and the decoder a multi-layered GRU with a classification layer connected to the last GRU of the decoder. The classification layer and the alignment model are fully connected layers with shared weights between timesteps. The proposed method is evaluated using data drawn from a commercial sound effects library, ProSound Effects. The resulting captions were rated through metrics utilized in machine translation and image captioning fields. Results from metrics show that the proposed method can predict words appearing in the original caption, but not always correctly ordered.