 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to Your Face: Inferring Facial Action Units from Audio Channel
Paper and Code
Sep 19, 2017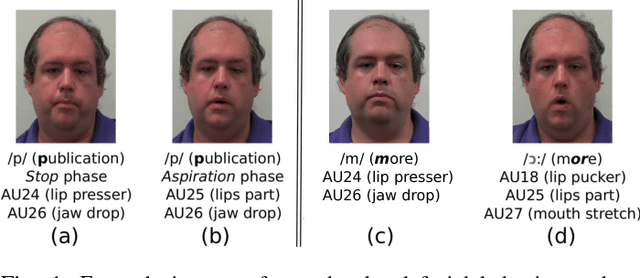

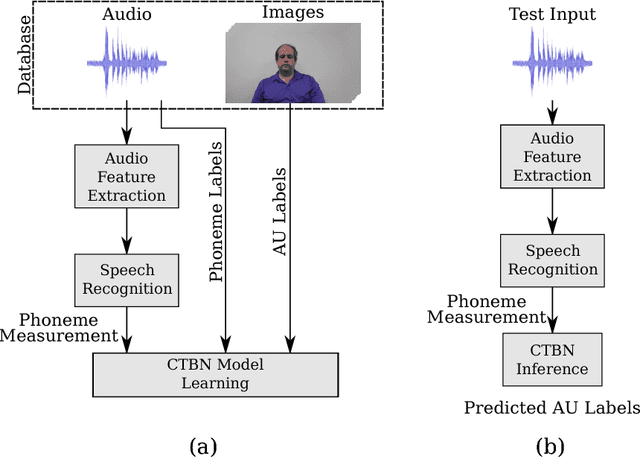

Extensive efforts have been devoted to recognizing facial action units (AUs). However, it is still challenging to recognize AUs from spontaneous facial displays especially when they are accompanied with speech. Different from all prior work that utilized visual observations for facial AU recognition, this paper presents a novel approach that recognizes speech-related AUs exclusively from audio signals based on the fact that facial activities are highly correlated with voice during speech. Specifically, dynamic and physiological relationships between AUs and phonemes are modeled through a continuous time Bayesian network (CTBN); then AU recognition is performed by probabilistic inference via the CTBN model. A pilot audiovisual AU-coded database has been constructed to evaluate the proposed audio-based AU recognition framework. The database consists of a "clean" subset with frontal and neutral faces and a challenging subset collected with large head movements and occlusions. Experimental results on this database show that the proposed CTBN model achieves promising recognition performance for 7 speech-related AUs and outperforms the state-of-the-art visual-based methods especially for those AUs that are activated at low intensities or "hardly visible" in the visual channel. Furthermore, the CTBN model yields more impressive recognition performance on the challenging subset, where the visual-based approaches suffer significantly.