 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning is Robust to Massive Label Noise
Paper and Code
Feb 26, 2018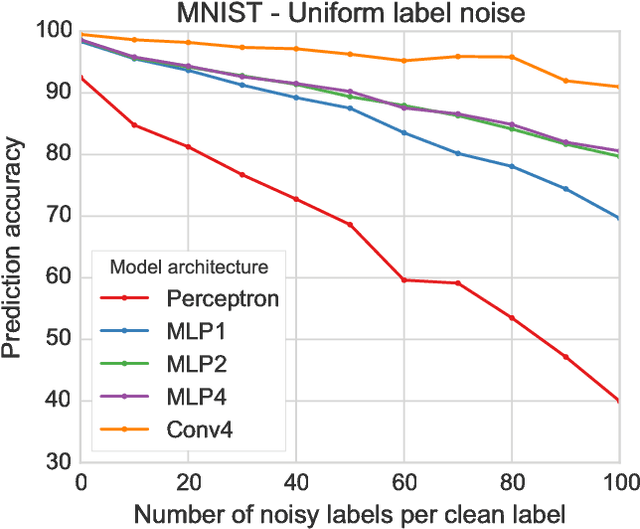
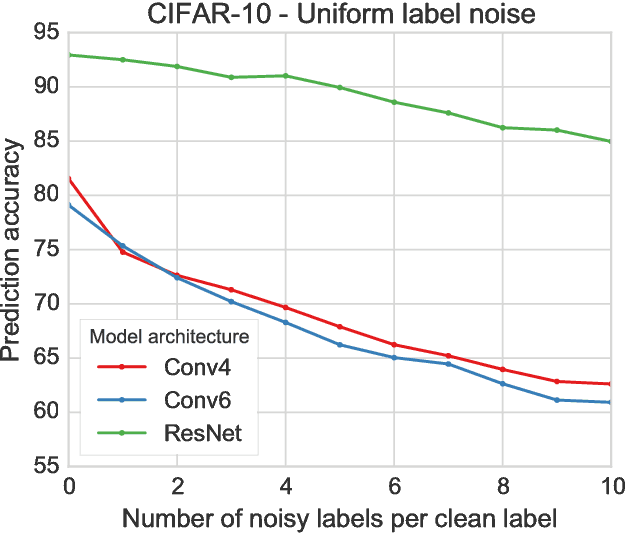
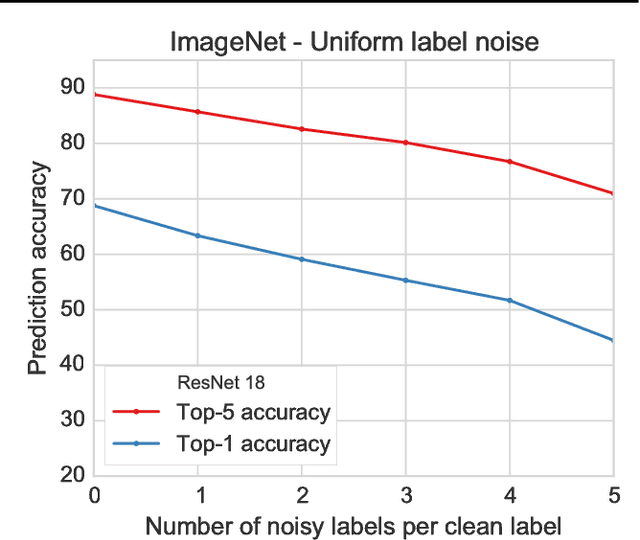
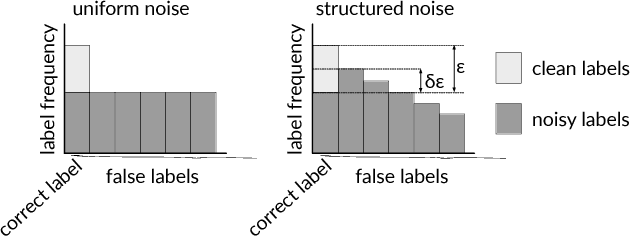
Deep neural networks trained on large supervised datasets have led to impressive results in image classification and other tasks. However, well-annotated datasets can be time-consuming and expensive to collect, lending increased interest to larger but noisy datasets that are more easily obtained. In this paper, we show that deep neural networks are capable of generalizing from training data for which true labels are massively outnumbered by incorrect labels. We demonstrate remarkably high test performance after training on corrupted data from MNIST, CIFAR, and ImageNet. For example, on MNIST we obtain test accuracy above 90 percent even after each clean training example has been diluted with 100 randomly-labeled examples. Such behavior holds across multiple patterns of label noise, even when erroneous labels are biased towards confusing classes. We show that training in this regime requires a significant but manageable increase in dataset size that is related to the factor by which correct labels have been diluted. Finally, we provide an analysis of our results that shows how increasing noise decreases the effective batch size.